Last Update 2023/3/31(刊行に伴い、更新は停止しています)
このページは,2023年3月28日にRoutledgeより刊行された書籍「The ICNALE Guide」(全236頁)の執筆作業の記録です。2007年に始まったICNALEプロジェクトの概要と、ICNALEを用いた学習者L2産出分析の様々な実例を紹介しています。
【進捗の記録】
《2023年3月》
3/4 e-bookへのアクセス権が送られてくる。海外の教員向けのinspection copyのシステムは進んでいるなと実感。

3/13 ハードカバーが国際便で到着。

2020/10/1に着手したので、ちょうど2年6カ月かかったことになる。ともあれ出来上がってよかった。
《2023年2月》
2/6 突然、出版社よりYour Book's Nearly Ready!というメール。SNSやメールの署名つけられる割引クーポンを発行するから著者も宣伝せよ、的な内容。ちょっと下品・・・という気もしなくはないが、このあたり、日本の出版社も真似られるところがあるのでは?
2/10 ORCHIDから論文が引用されたとの告知。見てみるとこの本からだった。なぜもうわかあるんだろう?
2/12 GoogleのcitationからA book cited your researchの自動告知。ということは本の電子データがすでにあげられているのだろうか?出版は3月なのだけれど・・・そもそも再校はないまま出版なのか??
2/17 Inspection copyの申し込み案内あり
《2023年1月》
1/1 index作りに着手。Gまで。途中、analytic/analyticalのスペル揺れを発見。まったく意識していなかった。25:30でぶれていた。。。
1/2 indexの続き、書き出しまで一応終わり。他の本を見ると、ページ番号に太字を使っているものもあるが、ないものもある→なしの方向で
1/3 ・indexのファイルへの入力、いちおう終わり。noun/verbなどは追い込みで関連語をまとめることに。
・気になっていた段落引用箇所の内容のチェックへ。6か所の確認と修正終了。
・Tableの数字割り付け確認
・Figureの数字割り付け確認
・編集指摘のTable/Figureの本体と目次のずれの修正を確認(対応済みだった)
・表の見直し再度(indexを見ていて表のフォーマットが壊れている箇所を複数発見)
・グラフ等のフォントの不統一に気づいてしまった。チェックが甘かったことに悔いが残るがママとする。
1/4 四章(語彙)以降の自己分析箇所の見直しを開始。4章、前回校正時にグラフがなかったこともあり、今回多くのミスを見つけてしまい本当に自己嫌悪に陥る
1/5 四章を終えて5章(文法)に入る。四章より問題は減った感じがする。5章、チェック完了。ここは問題があまりなかった。よかった。。。引き続き6章(語用論)に入る。
1/6 7章(個人差)のジェンダーの入り口まで
1/7 7章ジェンダー終了、14:00 7章全体終了。期限のあさってまでには終わりそう。
1/8 8章の途中まで。
1/9 AM1115 8章終了。9章に入る。1300いちおう9章までチェック。9章にもちょっとだけだが誤植(引用ミス)があった。その後レファレンスの書式をチェック。こちらがやっていた(2nd ed. )(pp.1-2)のような二重括弧を向こうが(2nd 3d., pp. 1-2)のように変えている箇所があったが、やはりちょっと変なのでもとに戻す。クリスマスからの修正作業がいったん終了。全部で280箇所もあった。申し訳ない。。。
1/10 早朝、先方より受領確認あり。仕事が早い。
1/18 原稿でtuition feesを誤用としていたが実例も多く、誤用の指摘を外すことに。気になっていたので連絡。
《2022年12月》
12/1~ 各章の自己分析箇所の読み直しと修正
12/6 修正をまとめて提出(1週間大変だったがいちおう全体を読み通せてよかった。直しすぎと怒られないか不安。とんでもなくつまらない内容なのではと不安だったが通読するとそれなりに意味もあるのでは、といくぶん気が楽になった)
最初の原稿の主な誤り
・Prodromou→Timmis(impositionの箇所の出典記載ミス)
・統計値を変えると有意性が変わる箇所に添えた統計値(※ランカスターのサイトで値を出したのだがもしかしてサイト側の問題?今回複数サイトで検証)
・origo関係の箇所でboosterを分析に含めていないことに気づき、図の差し替えを含む大規模修正が必要かと思って準備したが、先行研究から予想されたパタンの中で確証されたのは・・・だけ、というロジックを追加して対応(よく読むと元原稿を書いたときはそういうつもりだった気がしてきた)
・s/he→they これは先方の提案を採用したものだが、s/heを使った場合にどういう風に受け取られるのか欧州の肌感覚を知りたい気がする(古い? 性差別的? かたい?)
12/19 2週間ほどたつが反応なし。12/15にfirst proofということだったけれど遅れている? 別の仕事に着手しているのでもう1週間ほど返事がこないと嬉しいけれど。最初の原稿送付完了が5日遅れ。それでいくと12/20ごろ? 明日ぐらい???
12/24 到着、提出は1/9に設定される(教科書の重版作業中で、まだ開始不可)
12/25 教科書重版作業終了
12/26 とりあえず全体打ち出し。先に年末期限の別論文を仕上げてからこちらに移る予定。ざざっと確認。前回指摘は入っている感じ。Indexは何をすればいいかわからないので問い合わせメールを送信。
12/27 返信あり、Indexは当方提案通りでよいとのこと。
12/28 別論文執筆中。Cronbach=ICC (3,k)が一致することを別データで再度確認。ここが不安なところだったので、本のほうの数値も妥当性が確認された。
12/30 午後2時ごろ、タイ論文の提出終了。同時にBookのチェック開始。1600時点で3章まで終了。表がところどころおかしい… 12/31-1/1は小旅行のため再度中断。2130:7章までチェック終わり(Murphy 2010の引用が修正必要、あと、段落引用の書式が勝手に変わっているので修正必要。あと8章だが明日の朝に出来るか…?)
12/31 AM0940 前回校正の反映確認作業が一応終了(チェックしただけでPDF繫栄はこれから)。22:43 表と図について目次と本体の整合を確認(小括の表のタイトルに間違いが数か所あった。。。)。併せて表について5章まで体裁チェック終了。氷川きよしさんも歌っているし今年はこの辺までで。
《2022年11月》
11/23 近日中にedit原稿送付との連絡あり。少し遅れているが、こちらも今来ても1週間ではろくに対応できないので後しばらく時間が欲しい。
11/25-27 3回に分けてedit届く
11/26-27 対応作業開始、気になっていたCIAのモデル図の修正を指示
11/28 もう一つ気になっていたELFは比較しない、という一文を追加10/14 画像の質が低いものがあること、姓名の名表記にぶれがあり、hanover on holdとの連絡。それぞれ対応。
11/29 頭から見直す。Ch 1と2、いくつか修正発生。。。
《2022年10月》
10/29 今後のスケジュール通知
edited files with queries by 22nd November
return your review comments by 29th November
the first proofs for review by 15th December
return your corrections/comments by 29th December 2022
連絡が来るのがちょっと恐怖になっている。ともかくも11/22までに他の仕事をあげておかないと年末危なそう。
《2022年9月》
9/1 altテキスト完成、メインテキストのfigureとtextを本文でもすべて触れるように追加。並行して見つかった参照の表図番号のミスを修正。以上の修正いれたメインファイルからchapファイルを再作成。編集に送信。
9/2 着信確認あり。修正ないですね、と念を押されるが、yesと言おうとすると永遠に出せない。major changeはない、予定。。とお茶を濁す
9/5 endorsement到着(3人目)
9/6 タイトルを勝手に変えたのはなぜ?(会社としてHandobookという用語は別のシリーズとかぶるので使いたくない) →説明する(Asiaを出したい、など)
9/7 先方よりendorsementの省略の提案→承認→タイトル変更の確認
9/8 タイトル変更が了承される→前書きなどあわせて修正
9/12 作成工程に入ったとの知らせ
9/28ごろ ウェブに予告が出ているのを見つける
《2022年8月》
8/1 朝から参考文献の書式のチェックと欠損情報の補填。朝、いちおう提出。これでちょっとこの仕事は休む。→夏季休暇で不在通知が届く。代理の担当者に送信。
8/3 代理担当者から受理通知とprelimテンプレとチェックリストが届く
8/4 質問に対して出版社の校閲チェックがあることと校閲スタイル希望届が届く
8/5-7 図版データのPDF化(300dpi化)
・Word内のグラフ画像内のフォントを統一
・PDF化
・PDFを最大表示してSnipping Toolで切り出しこちらで300dpi化
8/8-11 文献表と本文の照合作業
・文献表にあって本文にないもの(※当初引用予定だったが書いているうちに消えてしま
たもの)について引用を追加。
・Excelで並べ替えたため、A&Bの&を拾って順序がくるっていた個所を修正。
・重複エントリを削除
・出版社の各種書類を準備
8/12 再提出、これで夏休み。。。のはず。
8/18 編集部より返信.
1) “Ch_00_Prelims”
・章タイトル最終か
・図表目次に漏れはないか
・blurb と author bioは問題ないか
2) Ancillary(付属)の詳細
・Index: 著者がやるか?
・Cover Design: ペーパーバックだけデザインカバーとなる,写真を送ることも可?
・図の品質 Figure 3 in Chapter 2の解像度が低い
・データシェアの場合は申請書を
・希望があればopen accessにしないか?(相談を)
3)Endorsements(裏表紙の宣伝文句)
・平均1-3人(献本がいく)を選ぶ
8/20
・図の内容を説明したalt-textの用意を(graphs or diagrams)
・Wordでまとめる
8/21
・章ごとのアブスト(オンライン版)が必要,1つのファイルに
8/21-25 他の仕事のためにこちらはおやすみ.
8/26 今ここ.会社の依頼(too much...)を整理.章アブスト作成開始。気づいた本体修正はtrack recordで記録。endorsementを依頼。
8/29 出版社より催促
8/29 数日以内に、と返事。endoesement1人分到着。
8/30 endorsement2人目到着、章アブストを完成、altテキスト準備。カバーのデザインを決める。endorsement2人分をファイルに。
8/31 altテキスト準備継続、途中で統計値の記載ミスを見つけて修正、カバー
《2022年7月》
7/1 Ch8のsummaryを新設。findingを表にまとめる。最後にdata triangulationの話を入れて9章につなぐ
7/2 Ch9の終章のみなおし、Gilquin(2022)のyardstick関係提案を整理
7/3 Ch9の終章のみなおし、統計のセクションの内容修正
7/4 se/zeのチェック。
7/5-19 別プロジェクト(日本語作文コーパス)のためストップ
7/20 二週間も離れていたのはこの数カ月で初めての用が気がする。。ここからテンションを戻すのが大変。もう、このまま送ってもいいかもしれないが、とりあえず冒頭章の読み直しを開始。なおいくつか誤植を発見して修正。
7/21 ICLE/LINDSEIの説明に関して、セクション内の構成を統一。参加者人数情報、POSタグ情報などを追加。★発見:エラータグとComputer-aided error analysisの話はV2のガイドにはあるのにv3では消えている。この辺なぜなんだろうか? エラータグの精度への懸念??
7/22 修正継続
7/23 修正継続
7/24 Data Typologyのところで表の中にある最後の項目の解説が落ちていることを発見。修正。
7/25 世界のLCの紹介の表で、1か所語数がずれている(S+WなのにWのみ記載していた)箇所を見つけて修正。approach/techniqueの記述を少しわかりやすく修正。
7/26 Chap1の見直し終了。Ch2の見直しに入る。Reference diversityのタイトルをAnti ENS centrismに変更。2.2.1 participant diversityは段落の組み立てを変更。
7/27 2.2.4 Metadataの修正まで。MotivationのところでStatements 2, 4, 5, 6, 7, and 11 concern an instrumental motivation, while statements 1, 3, 8, 9, 10, and 12 concern an integrative motivation. ・・の箇所、instrumentalとintegrativeをさかさまにしていたことに気づいた。巨額の費用をかけてすでに校閲に出したのに、このへんは見つけてほしかった。。。。 Proficiencyは大幅に修正。4つのデータを取った、順に解説、というスタイルに。
7/28 修正追加 Ch. 2まで。2.2.6 はdiversifying referenceから、opposing ENS centrismにセクションタイトル変更。より中身と整合した。2.2.7 Distributionで最近しったFAIR原則への言及を追加。
7/29 Ch. 3の修正開始。Ch2-3については、一般代名詞のweをやめて、the author と teamに変更。
7/30 各モジュールの説明を読み直し、わかりにくいところに修正を追加していく。
7/31 同上、Ch3の修正完了。GRAの確認テストの模範解答のミスを1つ発見し、修正。EEのキャリブレーションデータを分析したIshikawa (2018)を文献に追加。3人以上の文献をet al.に変更。
《2022年6月》
6/1 book-form文献からの引用追加継続。ザクっと本を読んでいると、CUPのLCR meets SLAの統計処理が例外的に高級だったことを再確認。
6/2 同上。Metadata収集に関して、proficiency dataの多様性に関する記述を改訂。learner-centered/ text-centred をわけることで、ずいぶん頭の中がすっきりした。
6/3~9 文献からの追加が完了。最終章を書くかどうか迷うが、なんとなく執筆を開始。Gilquin 2021などから引用を用意はするが話がごちゃごちゃして進まない。
6/10 最終章の(1) 一般化可能性、(2)learner/user、(3)モデル問題、(4) triangulation、(5) 統計、(6) metadataという形が決まり、(5)あたりまでいちおうは整う。
6/11 いちおう(6)までできるが、(1)と(2)が同じ話のような気がして1つにまとめる。途中、ICLEのC2が2割という話を入れかけるが、ELF理念は習熟度(だけ)ではないので、そこはカットで。
6/12 最終章見直し。metadataの話は前にもってきて、統計を最後に。その後にそれっぽい言葉を入れていちおう完成。参考文献のエクセルにスペルチェックかける。universityをstyなどにしている個所など多くあった。learnerのr抜けとか。人名はチェックがかからないので不安がある。最後にもう一度照らし合わせでのチェックが必要。参考文献表人名の表記ルール確認まで。
6/13 2) table / figure belowをすべて数字に変更。 ze/seを英国つづりに変更。score onをinに変更。
6/14 あとひとつ気になっているICNALEのanti ENS-centricism関係の話をまとめる件、ちょっと触り始める。
・冒頭でinterlanguageの概念を導出
・1.3.2 (CIA)のセクションにあったCIA批判の大部分を抜いて新セクションに移動・・・しようとすると、ぐちゃぐちゃになってきた。。。
6/15 それなりに整理終了。職場の同僚にcentrism/ centricismについて確認。
6/16 ENS centrism関係の変更点
1.3.2ではCIA批判はカット。ICNALEの特徴として、新設の2.2.6で、ENS centricismへのcountermeasureをまとめる。あわせて、本の中でENS centrismにかかわる箇所の整合性を確認。
6/17 Wordのspell check再
6/18 Grammarly再。learnerがleanerになっていたり、まだミスが残っていた。。。
6/20 墨俣一夜城でAsiaTEFL用の論文を執筆。
6/21 上記を書くときにやった追加分析が予想以上にうまくいき、本にも反映したくなってきた。Modellingとbenchmarkを無理やりくっつけていた最後のセクションを分割することを決めるが、結構面倒そう。。。 ★このページ、昨年の6/26に立ち上げているのでもうすぐ丸1年。そろそろ決着にしないと。とりあえず、8.3の圧縮を行う(得点予測だけに絞る)。OSRとORSの誤植を発見。。。
6/22 新8.4の執筆を進める。RQ5つの大型セクションになるが、話の筋はわかりやすくなった(はず)。作業の過程で、ICNALE SDのENSデータには職業バランスがないことを追記。
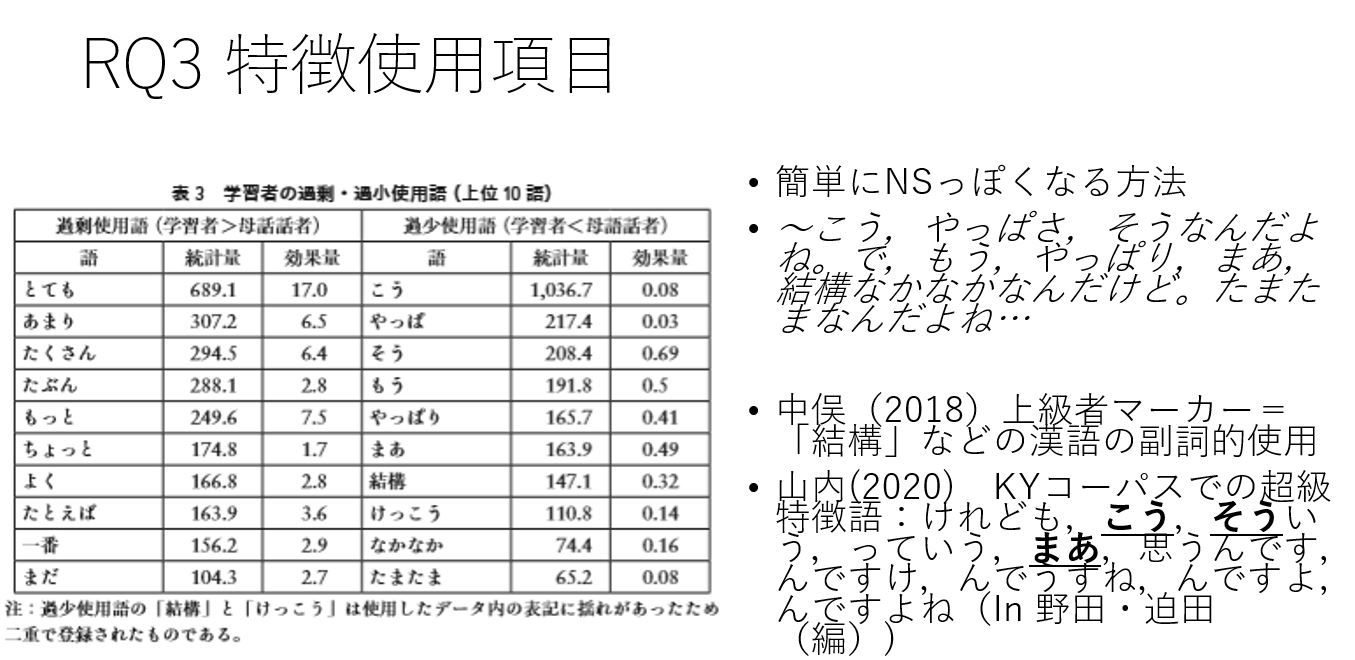
23 RQ1,2あたりを書きおろし
24 RQ 4までほぼ終えるが、RQ1のENS sampleのS/Wを入れ違えにして解説を書いていたことに気づき修正作業。
25 RQ1はENSの良い例と悪い例を比較していたが、ここの趣旨はENSは常に良いモデルではない、なので、悪い例だけを示すことに。RQ1の修正はほぼ終わり。
26 作業中にAsiaTEFL論文の誤植(ENSの連番を、本来番号でなくダミー番号と混同したため、異なるサンプルを用例に使っていた)を発見。訂正依頼出す
27 訂正依頼受理。訂正。そのほか本体RQ4まで修正。
28 朝訂正原稿をAsiaTEFLに送信。その後、本体修正続ける。タスクの概説を修正。keyword listでもよい、云々カット。speech終わってessayのsample comparisonまで
29 朝essayのsample comparison終わり(気づいていなかったが、low-level essayのlogicのねじれを指摘)、grammarly走らす。
30 出張で進まず
《2022年5月》
5/1 Sec 6.4(getsure)の反映完了。Table/ Figureのヘッダのボールドの不ぞろいをボールドアリに統一。7章に入る。
5/2 7章のイントロ修正、動機のところまで完了。Learning Historyで膠着する。
5/3 膠着継続中。元の話がとっちらかっていたので(input大事という話から、発信技能の指導不足の話になるとか)、はじめに4技能別の学習状況を知るべき、という主張を前に出してから、input/outputの重要性についてのSLAの主要理論の紹介を行う形に修正。新規にoutput theoryの解説を追加。終日作業して、19時ごろ、7.1節がようやく完成(短いのに)。アジアの生徒数が多い話など、関連の弱い内容を全カット。ICLEや最近のコーパスの学習履歴情報の収集状況の情報を追加。
5/4 genderのセクションの修正完了。樹形図を大きくするなど。
5/5 motivationセクションの修正に着手。前の章と文言などそろえる。比較の変数は文章から表に変更。結果の文言を修正。
5/6 結局大幅に変更してしまった。H_InCなどのHの記号を削除。特殊教育(スピーチとか)の経験区分をspecific skillsとかspecial experienceと言っていたのを、"additional learning experiences"に修正。冒頭章のmetadataのところも連動して修正。相関分析の解説もやり直したが、この節はどうも気に入らない。そもそも相関値低いし、相関分析とコレポンで結果がちょっとずれているし。。。いちおうここでfinにはするけれど。長すぎて?WordのスペルチェックがきかないのでGrammarlyをかけながら修正作業をしているが、既存個所のエラー指摘が700以上ある(学習者の引用などもすべてひっかかっている)。多すぎて目障りなので、Chap 3 までgrammarlyの指摘箇所をチェックして取捨選択。その後Chapter 8の各節の先行研究を冒頭に移動。
5/7 Chap 7までGrammarly反映。157か所に減った。Grammarlyがよく間違うもの:一方の意味の, whileのカンマを消したがる。, becauseのカンマを取りたがる(文法上悪くはないがGrammarlyは消す方向のよう)
5/8 Chapter 8の修正に入る。分析実例の前書きを全体のbackgroundに統合
5/9 新前書きの修正継続。Cronbachの記述の重複をカット、順序を変更。Reliability, Automated Assessment, Benchmarkのサブセクション構成に。追加の参考文献情報も入れ込み。
5/10 Backgroundに示した4観点の3と4を入れ替えて、全体の順序にあうように変更。そのほかもろもろ変更し、8.1 Introduction修正&Grammarlyチェックまで完了。
5/11 8.2(reliability)に入るが、Dataの説明がわかりにくく修正。
5/12 作業継続。2種のreliabilityのベースになっているデータの説明がややこしくその修正でスタック・・・
5/13 ようやく上記完了。その後8.3 (benchmark)に入る。speech rating→speech assessementに一括修正。用語のばらつきが所々に残っている。Dataの箇所の修正。
5/14 dataの箇所の微修正。RQ1の結果まで校正反映終了。
5/15 RQ1のグラフを表内から独立させるなど。
5/16 RQ1をもう一度見直しして内容的な手直しを追加。Set Bについて散布図とr2を追加。そのうえでr2は低いが、exaxt matchだけでなくnear matchまで含めると・・・という説明を追加(★この修正でだいぶ良くなった感じ)。adjusted r2の説明を追加。expected/predictedの用語ぶれ統一。散布図に単回帰式追加。RQ2の修正。説明の細部などを修正。スピーチ引用箇所について、ターンごとの改行に変更。
5/17 いちおうこの節修正終了。全体に戻って、気になっていた個所の統一。(a)(b)(c)はやめて(i)(ii)(iii)に。用例番号は連番機能でつけなおす。Chinese learnersとするか、learners from Chinaとするか、本当は後者が望ましいが煩瑣な感じもあるので統一必要。各節のsummaryの書き方の不統一も気になる。
5/18 表記の一括修正
1) B2 ---> B2+ 2) ESL and EFL 3) (a) (b) (c) ---> delete or (i) (ii) 4) 用例連番 5) Section Title: This Is A Pen 6) at [とるthe] A2 level 7) learners from China --> Chinese learnrs 8) 10 should be 10 [APAで確認] 9) Table/figureの文頭以外小文字統一 10)地の文のスペルを英国つづりに modelling analyze など
5/19 Summaryのまとめ表の出し方の統一(RQの知見を表に、具体例はカット)
4.3 具体的項目削除
4.4 記述を詳細化
5.2 表がなかったので追加
5.3 具体的項目削除
6.2 表がなかったので追加
5/20 Summary修正続 8.2 Assessmentのまとめ表を作り直し いちおう最後まで終了
5/21 進捗なし
5/22 Grammarlyの設定を英国に切り替えて再度かける。enhancementで表現を一部入れかえ。largelyとdifficultとimportnatが多すぎる Tableのタイトルの一括見直し
5/23 Figureのタイトルの一括見直し
5/24 同上続く。lexical diversity/densityの用語ずれを発見して修正。4.2のsummaryを少し圧縮。average-->原則meanに(参考)
5/25 いちおう最後までチェック終わる
5/26 以後、book publicationからの引用の追加作業。2冊の引用を追加
5/27 学会準備で進まず
5/28 Barth & Schnell 2022より追加。そのほか数冊追加。Section 1のAsian Learner CorpusをRecentl LCと分離、関連した相互参照の修正。learner/userの論文を末尾に引用。末尾章はENS model再考、learner再考、サンプリングの欠如再考(コーパスと呼んでいいいのか)、などの話でまとめる予定。
5/29 引用鳥を進める
5/30 LCR Meets SLA からの引用をまとめはじめるが、どの論文も統計がこむつかしくまとめるのにてこずる。しかしこんなに統計面で専門化?してしまうと、広がらないだろうなああ。
5/31 個人差に関してmixed modelとGriesのMUPDARの短い解説を追加。
《2022年4月》
4/1-2 追加文献のスピーチ語彙のセクションの整理を再開。
4/3 EFL/ESLの差異に関する部分のみを圧縮して本体に繰り込み。各研究の詳細はvoc研究に移動。
4/4 spoken voc関連研究を4タイプに整理。引き続いてwritten vocのまとめへ。
4/5 Written vocのまとめ続き
4/6 Written vocのまとめを一応終了。Vocabの章のイントロ(現在はTTRとかkeywordの概説で先行研究まとめになっておらずほかの章とずれている)について、現行のものをほぼすべて削除し、先行研究レビューのセットを新規に挿入。なお、lexical diversityについてはTTRだけでなく、R/C/D/ MSTTRなどの情報を追加。その後、合体版を仮に作成。体裁的に4.2と4.3を結合させるところまで完了(RQやmethodはほぼ同じなので合体は合理的な感じ)
★各章で、Introセクションと、分析の冒頭のAim/RQセクションの分量がまったくそろっていないのでどこかの段階で調整必要。(メモ)
4/7 Voc in speechesとVoc in essaysを合体した版に基づき、大幅なカットを実施。旧は、観察→統計→考察にしていたが、有意差がないことを論じるのは変なので統計→考察に。また、findingは表にまとめる。
4/8 合体部分の圧縮作業と見直しを進める。Spの平均語数の誤植を見つけて修正。用例出典の学習者の通し番号を追加。B1_2とB12の表記ブレを修正。今日の修正はSummaryの途中まで。
4/9 まず、table/figureの通し番号を全体で修正。その後summaryの書き足しをしていると、本体分析部分を削りすぎたことに気づき(どの国が何%ENSより少ないか、など)、再度合体章を見直して記述を補足。書式が校閲に出してくるってしまったので、手元にあったJones, Byrne, & Halenko (2018) Successful Spoken English(Routledge)書式に全体を合わせる。行数がかなり詰まった。
4/10 いちおうsummaryまで修正。その後最初に戻って、校閲の反映作業を行う。校閲は勝手に書式直してしまったようなものが多くちょっとirritating。英語のミスだけ直してくれたらいいのだが、それはほとんどない。。。修正作業の中で、Crystalのspeech分類の背景になっていたSurvey of English Usage Corpusへの言及を追加。
4/11 Sec 3.4.1まで校閲反映。
4/12 Sec 3.5まで校閲反映。その過程で、昨年度末に取得したEEの追加データ(3か国のB2+学生の校閲)をコーパスに追加。公式のバージョンを更新し、本の記述とウェブ情報を整合させる。※校閲者は前回とは別人であることを確認(業者が違う)。英語の""ではなく66-99の出し方がよくわからず調査したがなおわからない。
4/13 Sec 3.6の校閲反映。3.6.5 Data Processingの節を新設。新規に追加したエッセイの校閲データへの言及。3.6.6ではoverallスコアをanalytic sumに修正。サンプル評価者は1人減らす。
4/14 4.1-2に校閲反映
4/15 4.3に校閲反映、Dataの書き方をそろえる
4/16 4.4に校閲反映
4/17 ESL and EFLの語順を確定。
4/18 5章(文法)修正に入る
4/19 追加の参考文献の補填(本体に分析対象だけメンションしていたものをもう少し詳しくしてほかにそろえる)
4/20 参考文献補填について、当初はS/W別の整理を考えていたが、扱う文法事象別に修正。あわせてMDAや、文法発達についても、最初のIntroductionに糾合。量が増えたのでサブセクションの追加を検討。また、lexicogrammr/ coginitive Lなどについて引用を追加。
4/21 5-1 introductionの修正継続。Biber Taggerの解説は独立させる
4/22 同上
4/23 5-1の修正が完了。本体に張り込み終了。
4/24-27 5章の校正反映
4/28 6章の6.1 Introの修正。サブセクション追加。New approachesの節を独立させる。6.2のタイトルをdevelopmentからprgamtic devicesに修正。
4/29 6.2のType1/2の修正を契機に、6.1.1.2の先行研究をさかのぼって修正。関係する先行研究をほかの章からもひっぱってきて一か所に結合。6.2のグラフを微修正。RQ2については、関連のデータのみを示すグラフに変更。グラフは2枚×3種を1枚×3種に変更。記述全体を修正。いちおう6.2終わり。
4/30 Figureの番号ずれを自動修正。範囲指定→右クリック→フィールド更新。
《2022年3月》
3/1 EEのcalibrationの結果報告をここに追加。いちおう完成。
3/2 3章のみgrammarlyかけて昼過ぎ校閲に出す。現在の全体は71,643語。
3/3 他業務で執筆進まず。
3/4 他業務で執筆進まず。
3/5 参考文献リストの修正に移行。A-Gまで修了。ハイフンをエンダッシュに置換。
3/6 リスト修正完了。ついでIJLCRの論文リストにabst情報をリンク付け。最新の研究を可能な範囲で反映する予定(proof帰ってきてからになる)
3/7 進めず
3/8 Ch2のプルーフが先に納品。
3/9-15 ほぼ1週間,触らず(その間,Ch1のプルーフも到着)。
3/16 追記用に近刊論文の要約まとめを開始。
3/17 本体の目次を複写。各論文を該当箇所に割り付け。1/3ほど終了?
3/18 作業継続。3/2ほど?
3/19 作業継続,きちんと数えなおすとここでまだ1/3と判明。多すぎるかもしれない。どこまで取捨選択・記述圧縮するか。。。しかし主要なものだけでも過去の研究を網羅的に見ておくというプロセスは踏んでおきたいのだが。
3/20 学会参加で進まず。
3/21 別の学会の講演準備で進まず。
3/22 再開。
3/23 継続、いちおう最後まで終了。文献表データの修正に着手。
3/24 文献データの修正。各種コーパス解説に関する補充文献を本体に統合。
3/25 EFL/ESL関係のレビューをまとめるが、持っていく先がちょっと悩み中。1/5ぐらいに圧縮して、残りは語彙化文法のセクションに回すかどうするか・・・
3/26-3/31 新年度授業準備作業のため中断。
《2022年2月》
2/1 Ch 8のSummaryを書く。Introの後半の修正,この章の文献表作成。
2/2 Ch 8の世見直しを開始。冒頭のイントロのうち関係のない話をカット。組み替えるがぐちゃぐちゃになってきた。。。
2/3 高校の講話の仕事でほとんど進まず
2/4 修論試問他でほとんど進まず
2/5 evaluationという用語をassessmentに変更。冒頭イントロはLCとassessmentの関係の話に差し替える。また,イントロ部の話を,後の2つのcase studyの流れにあわせる。Case Study 1のみなおし~Case Study 2のRQ1のみなおしまでだいたい終わる。
2/6 RQ2の書き直し終了。benchmarkの例示の意味が曖昧だったが,discovery learningの実例提案として再定義することで節の趣旨が明確になった(気がする)。第2部の書き直しはいちおう完了。
2/7 第1部の引用文献を整理し,文献表を補填。IJLCRの収録論文をリスト化。
2/8 IJLCRリストの整理,LC around the worldデータの取り込み,冒頭セクションの構成修正作業着手。IJCLとCorporaの掲載論文リストも作成。LCデータベースの整理,ICCCなどの現状の問い合わせ。
2/9 学期末試験で進まず。
2/10 第1部第1節の修正に着手。先行研究の紹介を増やす。流れがちょっと悪い。replicability, falsifiability, total accountablityの話を加えることに。
2/11 Historyはだいたい終えて,各種のコーパス紹介のセクションに。アジア圏のコーパス紹介のセクションを新設
2/12 続いてapproac, technique, method関係をまとめ始める(新規にコーパス分析技術やや統計のさわりも)。当初cross-sectional/ longitudinalをコーパスのapproachとして紹介していたが,話しがあわないのでコーパス紹介に移行を検討。ぐちゃぐちゃしてきた
2/13 コーパス紹介セクションの最後にcorpus typologyのようなところを入れて,関連の話をまとめる。表を作ったので少し見通しがよくなった。その後CIAの記述の修正に入る。引用を増やそうとしたがまたぐちゃっとしてきた。。。それにしてもCAを念頭に置かない学習者比較をCIAと呼ぶのは筋違いな気がする(自分の過去研究も含めて)。CIAは結局はCAであり,その世界観を引き受けての比較なのだ,ということが大事。
2/14 1章がほぼ終わる。SLAとの関係のレビューを追加。20pだった1章は6pほど増加。
2/15 昨夜寝ながら,2つほど追加したい論点を思い出していたので朝,それらを追加。Gilquin 2021のone rule to them allの話と,LCAがdevelopment嫌い,という話。今日は別論文に着手したのでこれ以上進めず。
2/16 別論文が夜までにほぼ完成。夜,この本に戻って1行だけ書く。ともかく隙間を開けないほうがいいみたいなので。。。
2/17 ICNALE解説の章の修正を開始。ICNALEの特徴の数を減らして記述を集約。先行研究の引用なども増やす。(1) Participant Diverstiyのセクションが完成。
2/18 続いて(2) Data Diversityのセクションの執筆。Crystal 1995などをベースに話し言葉についても複数のタイプのデータがあることの紹介を追加。
2/19 (3) Condition Controlの書き直し。(4) Meta Dataの書き直し。
2/20 (4) Meta Dataの書き直しの続き。(5) multimodality修正。PrratとKinoveaの図版追加(どちらも久しぶりに触った)
2/21 (6) Data distributionを修正。いちおうこのセクションまで見直し完了。Grammarlyで英文のチェックをかける。
(自分メモ)
★upper intermediate→ハイフンをはさむ
★key word→1語に
★and →カンマを入れろ,もしくは抜け
★factors including a,b,c... →includinfの前にカンマを入れろ(※従わずにthat includeに修正)
★learners at B1 level →the B1にしろ
★leaner →rがうっかり落ちている個所が結構あった
★a variety of →単数扱いにしろ,これ本当かな?後でチェック。
・その後,直しがまだの3章をカットして,英文校閲に見積もり依頼。3章抜きで6万語ぐらいなので60万ぐらいか?
2/22 普通の論文校正と同じ単価ということで35万ぐらいになることを確認のうえ,発注完了。その後,昨日接種のワクチン(3回目)の副反応で起きていられず,執筆は停止。
2/23 体調回復して,今回校正に回せなかった3章(ICNALEの各モジュール解説)の見直しに着手。縦読みで各サブセクションの内容の不均衡をならすため,はじめに,各セクションのBackgroundの内容を修正。主要3モジュールの個所の修正が終了。
2/24 Backgroundの修正をそのほかのモジュールについても行う。
2/25 続いてParticipantsセクションを縦そろえで修正。作業中,EEのデータが一部補充可能なことに気付き,年度末予算で発注かける。セクション構造の埋め込みをやめてフラットに。
2/26 WEについてほぼ完成。トピック決定の理由を追加。SMについてはinstruction protocolを探し出してきて追加。SD, EEまで完了。あとGRAだけ。7万語をこえてきたのでこの辺で止めないといけない。
2/27 3.6 GRAの修正に着手
2/28 GRAのセクション構成を変更。rater/ ratingに。
《2022年1月》
1/1 個人属性章のイントロの修正を継続。genderは既存のLCにもデータはあるが分析に使用されない,motivationはデータもなく分析にも使用されない,という感じでまとめる。
1/2 ジェンダー分析と動機分析の順番を入れ替える。修正続けているが,どうもイントロの座りが悪い。
1/3 イントロの修正を継続。いちおうなんとなく格好がつく。章タイトルをlearner attributesから,SLAのカギ概念であるindividual differencesに変更。
1/4 genderセクションについて,先行研究を大幅に拡充。また,元バージョン(日本と台湾だけ4レベル比較)ではgenderの全体像をとらえていないので,元の分析をすべて放棄。B1にそろえて10+1群で比較する方向でやり直し。RQ1はANOVAにかける。RQ2-3はコレポンではなくクラスターに変更してやり直し。
1/5 大幅に変わったのでmethodの個所を修正。RQ1,RQ2の解説を書く。
1/6 RQ3の解説を書いていて,RQ2-3の手法上の矛盾に気づく(2は単語での話者分類だけ,3は文法タグつけて話者分類なしの特徴タグ比較だけ)。RQ2-3を再度修正,RQ2:単語&タグでの分類, RQ3:特徴的な単語&タグの抽出。また大幅な変更になる(このセクションなかなか終わらない)
1/7 RQ3は当初の調整頻度の20%+差を見るから,log likelihoodでの抽出に代えたので内容が総替えになったが,分析としての妥当性は増した。femaleのoveruseの解説を終え,underuseの解説へ。21:12 いちおうRQ3まで書き直しが終了。極限までぐちゃぐちゃになって次第に勝手に形が整ってくるプロセスは最後はそれなりに楽しいが,このセクション,修正ではなくほぼやりなおしになってしまった(コーパス研究はいつもこういう感じがする)。
1/8 summaryまで終了。もう一度セクションを見直して一応このセクション終了。明日から次へ行くっ!
1/9 JFICコーパス作業のため進まず
1/10 Section 7.3のintroの書き直しに着手。動機のことばかりなので,学習履歴含めて先行研究を増やすため,関連文献をチェック。
1/11 Introの書き直しを追加。書き言葉・話し言葉両方に分析を拡大することに変更。EFL@B1の学習者データを抽出するが,エッセイのほうが負があることと(動機のIntとInsの差分)1万セルオーバー(20変数×100人以上)で多変量解析が動かない。結局エッセイのほうは原則各国80本を抜くことで適用可能サイズに修正。コレポンだと関係見えないのでクラスターに。エクセルが巨大になりすぎて重い。
1/12 保存を忘れたのか,昨夜遅くまでっやていた作業ファイルが完全に消失。。。泣く泣く一からやり直すがその過程でアンケート回答者の中でも0のある人(スコアは1-9なので0は無記入の意味)が確認されたのでそれらを除いて分析をやりなおし。また,Sentence lengthはスピーチの場合無意味なのでそれを抜いてコレポンにかけるとそれなりにわかれた。あわせて相関は無相関検定もかけて値が低くてもなにか議論できるように修正。ファイルが消えたおかげで処理がより精緻化された印象。相関の表を作成し,分析を書き始める。
1/13 相関分析のセクションを新規に書く。当初essay/speech別に書きかけたが,考えなおしてlearner variables別に記載。当該セクション終了。エクセル統計はコレポンの際に変数のみの出力ができないため,RQ2のコレポンをHADでやりなおして解説を執筆。明日summaryを書けばこのセクション終わり。
1/13 Summary終了。このセクションの引用文献リスト入力。章内のIntroの不統一を修正。
1/14 8章のタイトルを修正。Intro修正の方向を考える。
1/15 今のintroは先行研究レビューになっていないのでそっくり没に。新たに参考文献を探す。
1/16 テストやアンケートで調べた学習者の習熟度 vs 産出物の実地調査で推定される習熟度の二階層の構成を示すうまい概念というかタームがない。そもそもL2 proficiencyってなに?ということで話が行き詰まる。いろいろ探してperformance-based assessmentなどの概念を紹介,あわせてautomatd assessmentの話も。しかし,バラバラで文でつながらない
1/17 先行研究のピースを組み替えていちおう話を通してintro部がようやく仮に仕上がる
1/18 8.2節のイントロの修正に入る。先行研究がなかったので,テスティング関係の先行研究を一から追加。テストの6要素をあげてその中のreliabilityについて検証するという方向に
1/19 イントロ修正を続け,なんとなくおさまる。運よく追加のratingデータが納品されたので,49+52=100という中途半端な数から,60+60=120でデータの分析をやりなおすことに。評価データの整理作業。あわせて級内相関係数のType 1/2/3の復習。まだどうもよくわからないところがある。あと,評価者内の信頼性で測るのは評価者の信頼性なのか,テスト(今回はルーブリック)の項目の妥当性なのか?いずれにしても違う側面をいろいろ図るのでずれているのは悪いのか・・・?など。
1/20 ICCの2と3の差はなんとなくわかるが,3,1と3,kの差がどうもぴんと来ない。エクセル統計の見本は3,k。海外文献だと結果を一般化できない3.kはrarely usedともある。今回の場合,どちらになるか。。。エクセルで16000行の列を140行ごとに分割する必要が出てきてマクロを触るがうまく動かない。海外ソフトを見つけてようやく解決。これで評価者間のICCはクリア。評価者背景ごとのグラフまで作成。RQを再整理して評価者間信頼性と,項目間一貫性の2本に変更。ちょっと先が見えなくなってきた。
1/21 心理学の教科書からの引用でセクションのイントロを書き直し,3つの信頼性,そのうちintra-rater reliabilityは1回評価だと関係ないので,ルーブリックのinternal consistencyとinter-rater reliabilityを論じる,というストーリーに作り替え。いちおう話が通る。これにあわせ,RQ1と2を入れ替え。先にルーブリックの項目検証(ICC+クラスター。重回帰はカット),後で評価者間の分析に。数値計算,グラフ作成終わって論文に張り込み。
1/22 Summaryを書き,最後にmethodに戻って書き直し,一応このセクション終了。明日もう一回見直してfix。
1/23 章イントロを再度読み直し。議論があちこち飛び交っている個所をカット。8.4セクションの修正にあたり,anchor sampleをbenchmark sampleと言い換え。benchmarkを見つけることと,自動推定の話がちょっとつながらない・・・Evaluation Data Applicationにしてbenchmark抽出+自動推定に。サンプルごとの評点データを書き出そうとしているうちに元ファイルの転記ミスを発見。 W_Rater060(S_Rater_063と同一),09→正しくは100,90~99→100~109,19→110。また,W_Rater_032のrotomgはEssay_047の誤記。以上修正。項目検証(項目ごとに60人の評価者の平均を比較),評価者比較(評価者ごとに140本の平均値を比較)には影響しない。
1/24 先に新データでの分析のやりあおし作業を終える(自動推定の話を前に,benchmarkを後に),その後,8.3節のイントロの書き直しを開始。
1/25 元のイントロはbenchmarkの話しかなかったので自動推定の研究のレビューを新規に追加。精度などの情報が入って自己分析との比較がしやすくなった。いちおうイントロの修正作業はほぼ終了。
1/26 他の仕事をしていたためほとんど進まず。上記の追記個所の数値を修正。
1/27 Data and Methodを一から書き直し,RQ1の分析を途中まで書く。
1/28 RQ1の分析を仕上げてRQ2の分析に入る。
1/29 RQ2継続
1/30 RQ2継続,ほぼ完成。
1/31 他の仕事でこの日は何もせず。
《2021年12月》
12/1 いろいろ書いているうちに,ふとここを話し言葉・書き言葉・書き言葉校閲の3つのkeyphraseにしてはどうかというアイデアに至り,すでに書いていたphraseologyの章の書き出しを4章のイントロに結合する。
12/2 上記の仕事をやりかけて,やはりkeywordsがなくなるのはまずいと思いなおし,方針を再修正。話し言葉&書きことばのkeywordのセクションと,原文・校閲のkeyphraseのセクションの2本立てにする方向に再修正。そのうえで,keywordに関してGranger ed 1988などの過去の研究のレビューを作成。
12/3 スピーチデータを処理,keywordを網羅的に取る
12/4 エッセイデータを処理,スピーチとエッセイについて群別とcommonのkeywordを整理して表の形にする,スピーチについての分析を書く
12/5 エッセイについての分析を書く
12/6 エッセイ分析に群特化型の特徴を追加,summaryセクションを追加。これで4.4がいちおう完成。次に行く。
12/7 この日は事務作業をやっていて執筆に手つかず。
12/8 Phraseologyのセクションに入る。結局,origina/ editについてkeywordとkeyphraseを出す構成とする。LancsBoxでkeyphraseの取り出しに成功(なかなか慣れない)。keywordの部分について前に書いていたものを一部再利用しながらほぼ完成。明日はkeyphraseへ。
12/9 keyphraseのセクションを執筆
12/10 keyphraseとsummaryを一応終える。目次の修正。未完のセクションの特定
12/11 VocabularyのIntroの一部修正,GrammarのIntroの書き直し,先行研究のレビューの追加。
12/12 GrammarのIntroの書き直しまでほぼ終了。
12/13 GrammarのICNALE Studiesを書き直し。第1課題を大幅に書き直し(文法能力の向上のテーマにしぼる)
12/14 Sec 5.2 (文法能力の向上)のセクションを完全に書き直し(Two-way ANOVAで検証,元にあった5観点の評点間相関や総合化などは趣旨ずれのためすべてカット)
12/15 Sec 5.3(MDA)に入る。元のintroを大幅に修正。RQ1と2を入れ替え。
12/16 新しい構成でmethodを修正。続いてRQ1(タグ分析)を書き直し。タグの実例をBiberでなく実際の単語に置き換え,分析実例を差し替え。中国人学習者のところまで終わり。明日同じやり方でENSをやる。
12/17 ENSについて最適の用例を探して記述を書き換え。続いてRQ2(次元スコア)の修正に入る。参照する他のテキストタイプのデータを追加。Summaryを新設。MDAの広がりを抑止した原因について簡潔な要約をつける。5章文法はいちおうこれで全面修正が終了。初版よりはずいぶん話のとおりが良くなった気がする。
12/18 (本日は,JFICコーパス作業のためこちらはお休み)
12/19 PragmaticsのIntroを全面的に書き直し。literature reviewを大幅に拡大。
12/20 Introがほぼ完了。第1課題に入る。草稿では発話におけるorigoだけだったが,エッセイにおけるmodal/ intensifier/ origoの3観点分析に変更。全面的にやりなおすことに。頻度調査を開始。1/8ほど終了。
12/21 頻度調査の残りに正味丸5時間かかる(もっと合理的な方法があったかもしれない)。中国人データでindividualとmergeの一致を確認。全体比較のグラフ作成まで。
12/22 RQ1をほぼ執筆。RQ2(変数が多いのでA2 vs B2のみ)の作図まで。
12/23 RQ2の分析をいちおう書き上げるがだらだらした説明になっている感じ。
12/24 RQ1について図・解説・図・・・方式をやめて,図をまとめてその後で解説をまとめる方式でシンプルに整理。同様の方針でRQ2も書き直し。これによりRQ1で得られた4つの傾向がRQ2で2つに絞られるという線がクリアになった。続いてSummaryの執筆。このセクションいちおう完了したので,元の6.2(インタビューデータに対するorigo-nearer/farther分析)をすべてカット。その後,6.3(politness)の修正に着手するが,この話の前提としてIntroductionにpolitenessの話を追加。あわせてIntroductionのそのほかを微修正。その後6.3に戻り,6.3の導入部の修正まで。このセクションはあまり触らずにいきたいが。。。あと1週間でなんとか,ジェスチャー分析の新セクションの完成まで行きたい。
12/25 Leech 2014などを読んで前提をかためる
12/26 HKGとPHLの順番を入れ替え,3つのface対応方向があることを命じ。分析を詳しくするが,ピンボケが増している気がする。
12/27 これまでは学習者のpoliteness controlを論じると言いつつ,学習者と教師の対話分析になっていたことに気づく。発話用例をひとまとめに提示し,教師発話の分析をすべてカット,学習者の個々の発話におけるpoliteness controlに限定して整理。一応話が通ったのでsummaryまで仕上げる。前よりはよくなった(と信じたい)。その後gestureのイントロを書き出す
12/28 Ishikawa (in press)のデータを再分析するかどうか検討。男女を分けるか? 新しいデータで日本人だけのA2/B2比較にしようかと考えたが,数が多いほうがよいと判断し,in pressのデータから日中だけを取り出して再分析に。in pressではかけていなかった統計分析にかけると差が出なくなったので,記述を新しくする。RQ2は実例分析にする。ビデオから静止画を取り出すソフトとサイトを試すがうまくいかず,元のデータをクリップして,タスクの場所のみを切り出す。

1) mp4をMSの「フォト」で開く
2) 右上の編集と作成→トリミング
3) 下のバーの左右の白丸を真ん中に寄せて残したい区間を指定
4) 名前を付けて保存(※トリミング実行,的なボタンがない)
5) youtubeにあげて自動字幕をつけて画像を見ながら重要なシーンを手作業でクリップ
その後,日本人2人分のビデオを処理して,簡単な解説を書く
12/29 日本人だけではバランスが悪いので中国人2人のビデオを処理してアップ,最終的に,日本人中級2名,中国人上級1名について解説をさらっと書く。その後,もう一度最初に戻って,gestureのfluency marker/ disfluency markerの2説あることを追加
12/30 youtubeの自動字幕はミスがあるので,手作業で正しい字幕を付けなおして画像を修正。各人の発話内容を細かく補う形で3人分の解説を書き終える。イントロのCase Studyのセクションを書く。Corpus Pragmaticsの最新号をざっと見て取り込める研究を探す。いちおうこの章終わり。目次修正。参考文献をエクセルに移行して管理開始。
12/31 個人属性のイントロの修正に着手。
《2021年11月》
11/3
再開。Genderのセクションを一応仕上げる。次へ行く!
11/4
Rating章の前書きを書き始める。10/31-11/2に準備した発表と内容が重なるのでこの章は分析はほぼ終わっている。
11/5
昨日書いた前書きがだらだらしていたので少しカットして書き直し。実例1の前書きまで。
11/6
研究実例に入る。RQ2を先行させ,S/W別に平均スコアの比較。
11/7
やはり統計をかけるべきかと思いなおし,RQ2をANOVAで処理。あわせてRQ3用にクラスター分析。
11/8
上記に基づきRQ2の分析部分(ANOVA)まで書く。
11/9
続いてRQ3(クラスター)の考察を書く。戻ってRQ1(ICC 3, 1/k)を書く
11/10
エクセル統計のガイドに従ってICC3でやったが,別文献で,評価者を決め打ちの母集団ではなくサンプルとみるのがふつうでICC2が標準,ICC3はrareだという見解を見つける。納得して2に変更してやり直しかけたが,やはり,今回の場合,ここまでで集めた49人なり51人の実態の報告が目的で,generalizeするものではないのでやはりICC3でよい,と,いちおう自分の中で仮決着する。手法の欄を書き終える。見直すといろいろありそうだが,とりあえず次へ行く!
11/11 2つめの実例分析に入る。introを書き,RQ1,1つ目の分析を実施(ANOVAで差の検証)。全体のRQは模索中だが,(1)習熟度とスコアの関連,(2)上下だけでなく各レベルのanchorの抽出,(3)コメント分析,(4)言語特性分析,の4つぐらいで計画中。ベースになった口頭発表では(2)は上下だけで(3)はやっていなかったので,何が出るか(出ないか)楽しみ。
11/12 上中下の3段階にしたが,もしかすると20%刻みなどのほうがアンカー性が高いかもしれない。と思いなおす。
11/13 Level A=Fにわけて再分析。
11/14 上記に基づき,考察を書き上げる(RQ2終了),個人的には面白かった。とくに,同じアジアのEFLでも,W>>Sなのは日本と台湾で,むしろ他の国はW << Sである点は示唆に富む。
11/15 RQ3(良いスピーチ悪いスピーチ,良いエッセイ悪いエッセイ)の実例分析,終了。Essayのデータをレベル分類。
11/16 Speechのデータをレベル分類。作業中にICNALE SD V1.2内のKOR_016の習熟度コーディングミスと,transcriptシートのデータのみ記載を発見し,修正のうえ,ICNALE SDのV1.3として公開,ウェブサイトの修正。Essayとspeechについて,rating level別のキーワードを抽出。
11/17 rating level キーワードについての考察を追加。キーワードの話と,サンプルの質的評価の順序を入れ替え,analytic scoreのレーダーチャート追加,Data and Methodを執筆,1つ戻って8.2のほうのまとめを追加。あと,8.3のまとめだけ残る。★まとめは,summaryなどにするかどうか考え中。
11/18 RQ修正
11/19 RQ修正,小見出し修正。9章を除くといちおう形は出来上がった。現在20万語,170p。資料,索引,参考文献で20pとすると現在約190p程度か? 以後は,新章書き足し(Phraseologyを予定)の前に,関連の先行研究を整理して各章・各分析に入れ込んでいくことを優先する。
11/21 と思ったけれどやっぱりphraseologyの章を書き始める。
11/22 と思ったけれどやっぱりvocabularyの章の拡張のほうを先行させる。
<加えたい分析>
・語彙の基礎指標(語彙多様性,品詞,語彙レベルなど)の分析
・語彙からの習熟度推定
・ジェスチャー
11/23 語彙の基礎指標分析に着手。データ,グラフを作成。語彙レベルだけまだ。
11/24 essayとSDのpicture description speechで比較していたが,speechは別の章にSMの分析があるのでかぶるのでカット。
11/25 mergeデータに基づいて一応書き上げるが,次の章との処理のずれが気になる。
11/26 絶賛迷走中。結局,Vocabularyセクションの章ごとのデータの不釣り合い(EFLだけやるかESLもやるか,mergeでやるか,個別ファイルでやって統計かけるか)が気になり,再度,ゼロから,WEとSMについて,個別データの語彙解析からやりなおし中。統計処理まで終了。
11/27 4章,語彙のIntroを全面的に書き直す。続いて4.2.3.1のRQ1まで終了。つづいて4.2.3.2のRQ2に着手。
11/28 4.2をいちおう完成。前版(国,習熟度,トピック,回数比較のみ)よりはかなり分析が詳しくなった(最初に各国レベル別のグラフ概観→3要因の統計検定)。新たにsummaryセクションを新設。≒は ≈ に全部差し替え。
11/29 同じパタンで4.3を一応完成。topicの検定をbetweenにすべきところwithinにしていたのでその個所の検定をやり直し。重くて動かなくなったのでエクセルの作り替え。
11/30 昨夜作業したwithin検定に基づいて書き直し。用例を2~3か所ずつ追加。いちおう4.2(スピーチ),4.3(エッセイ)が完成。元版よりはかなりすっきりした印象。引き続き4.4(特徴語)の書き直しに入る。従前はエッセイの国別・習熟度別・改訂前後別だったが,Spも特徴語も入れる方向で改訂予定。
10/1-3 学会準備で中断
10/4 再開。Ch. 4-2 (fluency)のRQを再設定。RQ1/2のデータを見直して分析部分を書き上げる。統計ソフトをエクセル統計からHADに変更(ANOVAの際に偏η2が出るので)。★しばらく空くと調子が戻るまで半日かかるので毎日数行でも書き続けるほうが効率的。
10/5 4-2-RQ3まで終了。分量が多いのでvocabulary関係では例題2つまでとして,4-3 をkeywords analysisに決める。RQの確定。データの下準備
10/6 4-3のRQのみなおし(1:中国人学習者の過剰/過少,2:中国人学習者の習熟度別,3:校閲の過剰/過少)。RQ1-2の執筆。RQ3書き始める。ファイルにページ入れ。
10/7 RQ3の執筆終了。→ 完成したものの,あまり面白くなく,かつ中国人だけではインパクトが弱いのでRQをつくりなおし(1:EFL6か国別,2:校閲別)。RQ1終了。RQ2に着手。
10/8 RQ2完成。その後やはり習熟度別が必要と考え,新しいRQ2(習熟度別)を追加。用例追加。いちおう仮完成。
10/9 5章に入る。5-1,5-2の最初まで。
10/10 5-2の2つのRQ(文法能力・語彙力×5観点の相関観察+総合観点との相関観察)でデータをとる。いちおう書いてみるが,習熟度を見ていないので,習熟度別,国別も追加で調査実施。RQ組み換えを検討。
10/11 習熟度,国別を見たがどうもすっきりしない。
10/12 迷走中。どうも納得がいかない。語彙vs文法というデザインでは見たいものが曖昧になるので語彙を思い切ってカットする方向に。また,基礎観察としてedit数の習熟度・国別比較を追加。edit数はトークン数で補正する方向に。・・・1日がかりでいちおう形ができる。深追いせずに次のセクションへ。
10/13 Ch 5-3(MATを用いたMD分析)着手。ほぼ完成。明日から次へ。
10/14 大学で語用論関係の論文を収集。コーパス語用論研究の様子を整理。
10/15 Ruhlemann 2019をベースにして語用論の章のイントロ執筆。6-2の例題1の方向を固める。
10/16 6-2の書き出しを執筆
10/17 (1) origo-near/farのセット語をサンプルで検索して頻度取得,統計かける
(2) existential thereやcomplementizerのthatなどの混在を確認→一度結果を破棄して,手作業で分類作業(途中)
10/18 手作業分類を終えて,話者集団ごとにorigo-near/ farのt検定にかけてみるが,もしかしてnear率を目標変数にしたANOVAにすべきであったのでは,という気がしてきた。また一からやり直すのは面倒だが,納得がいかないままだと考察がしづらい。その後,やりなおしたが,なお思ったようにきれいな結果が出ず迷走。共起グラフなども作ってはみたが,趣旨が混濁。
10/19 シンプルに戻り,origo-nearer比率をJLEとENSで比較。その後,各タイプごとにOrigo-nearer のbigram/trigram(後でtrigramに一本化)を比較。
10/20 朝,いちおう6.2が仕上がる。次へ。
10/21 6.3の前書きを書き始める(turn taking)が後の組み立てが固まらない
10/22 turn-taking関係の先行研究などを整理。なんとなく方向性を決める。この節は,計量でなく,質的観察の方向で。
10/23 とりあえずB2の2つのサンプルを選び,これを質的に読み解いていく方向で,RQ1とRQ2をいちおう書いてみる(が,turn takingがそれほど面白くなくいきづまる)
10/24 冒頭のintroを全面的に書き直し,turn takingの話は総カットでpolitenessに限定,その線でRQ1の書き直しを進める
10/25 RQ2の書き直しまで進め,いちおう(いまいち気に入っていないが)形としては終わる
10/26 新章に入るが,当初はRatingだったがLearner Attributesの章をはさむことに。章前書きを書く
10/27 データを作る,その過程で日本人データでアンケートが欠損しているものが相当数あることを再確認。
10/28 対応分析にかけるが結果が読みにくいのでクラスターに変更。RQ(動機+学習履歴)はクラスターにする関係で1つにまとめる。考察を書くとおよそ適量に。
10/29 次節へ。genderとsexの関係について解説を書く。ICLEの対応についてもまとめる。JPNとCHNの発話全体で分析することに。発話量? 語彙? 文法指標? 全部?
10/30 文法タグ付け
10/31-11/2 講演・発表の準備で執筆中断
《2021年9月》
9/21 第2章(理念)の残りを執筆。従前6つであった理念に新規に2つを追加(multimodalとediting/rating)
9/22 第3章(モジュール)に入り,Written Essaysを執筆。Edited Essaysに着手。
9/23 Edited Essaysを完了。続いてSpoken Monologuesのセクションを完了。
9/24 Spoken Dialoguesのセクションまで完了。3章の構成をみなおし,各セクションに3 Collected Dataを加える。
9/25 Global Rating Archivesをほぼ完了。
9/26 Global Rating Archivesを完了。各章の冒頭に導入を記載。2章のサブセクションを整理。8つの理念のセクションレベルを1つあげる
9/27 Ch3 Moduleの冒頭に全体を概観するセクションを追加。Ch.4 Vocabularyについてイントロ,各セクションの例題,1つ目(fluency)のRQ設定を追加。
9/28 高校出張で中断
9/29 JAECS発表準備で中断
9/30 DSコンテスト審査で中断
《2021年夏以前》
Year 2021
2/5 全面的に企画書を改訂し,B社に提出
4/28
フィードバック受け取り
4/29 proposalの修正と再発送
5/5
外部評価者コメント(1名)到着
6/12 企画の状況確認を督促
6/24
再度督促,前向きの返事が来る
6/25
2名の外部評価者のレビューシートが到着
6/26
テンプレートを作成し執筆の準備に入る
7/5 proposal採択の内示
7/12
出版契約(オンライン)
-- 7/30
第1章(序説)を執筆。2章(理念)の前半を執筆。
-- 9/15
学期末処理・新学期準備ほかで執筆が中断
9/18
執筆再開。本エントリを作成して進捗管理を行う。
Year 2020
10/1 Book Proposalの作成を開始
10/11 A社にProposalの送付
10/13 フィードバック受け取り
10/14 修正プロポーザルを提出
11/07 シリーズ趣旨と不一致という連絡あり。proposalを取り下げ。
メモ 分量の変化
===========================================
【2021/12/30 時点 約5.5万語----※最大7万語まで)
【2022/1/14時点 5.9万語】
【2022/2/6時点 6.2万語】
【2022/5/20時点 7.3万語】
【2022/7/4時点 7.9万語】
【2022/8/12時点 9.2万語】
【2022/9/1時点 9.2万語】
【2022/12/26 初校】 226p (index除く)
============================================