下記にオンライン参加し、発表を行いました。
THE 6th UHAMKA INTERNATIONAL CONFERENCE ON ELT AND CALL (UICELL)
Theme: “Multilingualism in Digital Language Teaching and Learning Environment”
December 22 – 23, 2022

学会概要

キーノートの一部

石川の発表
下記にオンライン参加し、発表を行いました。
THE 6th UHAMKA INTERNATIONAL CONFERENCE ON ELT AND CALL (UICELL)
Theme: “Multilingualism in Digital Language Teaching and Learning Environment”
December 22 – 23, 2022
表記(オンライン実施)で講評を行いました。

オープニング


研究室に多数あった古いパソコンの処分を行っています。半数はデータ消去ソフトで処理できましたが、残り半分は古すぎたり電源が入らなかったりしたため、専門業者に出してデータ消去を依頼しました。その中の1台。

表記に参加しました。
Monash University | University of York | Thammasat University
INTERNATIONAL HYBRID CONFERENCE ON DIVERSITY AND INCLUSIVITY IN ENGLISH LANGUAGE EDUCATION
9-10 December 2022
3大学で毎年回しているイベントということで、アジア・豪州・欧州の研究連携の良い例だなと思いました。

石川発表:Assessment of L2 English Speeches: The Influence of Rater Backgrounds


全般
同じクラスでも学習者はみな異なる
よい教材は、学習者による教材のlocalise/personaliseを可能にする
自分の暮らし、自分の家族、自分の経験を教科書に入れ込めるなど
米国の映画、米国の食べ物を扱う教材→ベトナムの映画、ベトナムの食べ物に変えるとベトナム学生の反応は変わる
教科書は、スクリプトを追いかけるように設計されているが、学習者がそれらを改変する機会を与える
教科書の問題
1)homogenenityを前提にする(B1学生対象など)
2)PPP型教授法(※イラストや見かけは変わっても根本は一緒)
3)学習スタイルを規定している(studial=analytical)
4)線型的発達を前提にしている
5)regularityを押し付ける(有る単元の時制は1つだけ)
6)知的な挑発(provocation)は回避される(登場人物はみなハッピー、葛藤もなく、全員バラ色の世界・・・)
7)全部のcoverageを要求する(教師の満足にはなるが学習者のニーズとは異なる)
教師の問題
1)標準化された行動を要求
2)こうあるべき、という標準的期待を持つ(話せ話せと要求すると話せなくなる)
3)最適基準(standard)は学習者個々のものなのに教員が一意に決めつけ
学校の問題
1)学習者をテストにかける(テストの時間に学びは発生しない。時間の無駄)
2)全員に同じテストを課す
3)テストのターゲットを一意に固定
→対応:競争的テストの廃止、testing to learn(テスト準備自体が学びになる、テスト自体が学びになる)、個別化された評価 ※MATSDA研究会での活動
個別化(differentiation)の価値
効果的に学ぶには、感情的/認知的に没入(engaged affectively/cognitively)することが必要
個々のタスクは、異なる形での没入をもたらす
学習者はテキストやタスクを過去の体験に接続させる必要(個々の学習者の経験は違う)学習者はrich, recycled, and meaningfulなL2 in useへの接触が必要
学習者はL2使用について自ら発見する必要
学習者はL2を自分自身のコミュニケーション目的で使用すべき
学習者に与えるべきチョイス
level, 参加、言語、方法論、教師、仲間

下記に参加しました。
国府台言語文化教育研究会
(Konodai Association for Language and Culture Education, KALCE)
第 2 回 研究会
□ 開催日時 2022 年12月 3 日(土) 14:00~17:00
□ 開催場所 和洋女子大学国府台キャンパス東館7F 演習室2
次 第
14:00~14:10 趣旨説明と講演者紹介: 拝田清(和洋女子大学)
14:10~15:10 ミニ講演: 村田年先生(千葉大学名誉教授・元本学教授) 「私の勉強と研究 ― 若いころを中心に」
15:20~15:50 発表練習: 堀由紀・アシュール真弓(大学院科目等履修生) 「英語科と国語科の連携を視野に入れたローマ字指導の一考察」
16:00~ 指導・講評,情報交換など


★村田先生のご講演では、日本語には主語省略が多いこと、日本文学の英訳では、主語の誤訳が多いことなどのご報告があり、大変示唆に富む内容でした。主語と動詞が離れて、動詞だけが存在する場合、その動詞の主語を直前の内容の中にあるどの名詞に帰属させるのか(前方照応)は難しい判断ですが、村田先生は、主語部に付属する「は」と「が」の違い(取り立ての「は」はそれ以降の広い範囲に影響を及ぼし遠くの動詞も支配できる一方、「が」は直後の内容を狭く指す)で、照応関係が決まっているのではないかという知見を示され、大いに納得するところでした。
★私にとっては3年ぶりの対面学会・研究会への出張です。行くまでは不安でしたが行ってみると移動の勘が戻ってきた感じがします。コロナ前は月に1,2回ぐらいは東京に出張していたことを思うと、隔世の感があります。
下記に参加しました。
日時:2022年11月26日(土)午前9時30分から11時45分
開催形態:オンライン(Zoom)開催
プログラム:
9:30 ~ 9:35 開会の辞
9:35 ~ 10:15 森口稔先生 「非母語話者向け日日辞典の概要と語義記述の特徴」
10:20 ~ 11:00 Vincent Ooi先生 ‘Modelling English use in Japan and Singapore for the dictionary’(英語によるご発表)
11:00 ~ 11:05 休憩
11:05 ~ 11:25 ブレイクアウトセッション(参加者間)
11:25 ~ 11:45 Q&Aとディスカッション
11:45 閉会の辞
森口稔先生(京都外国語大学)「非母語話者向け日日辞典の概要と語義記述の特徴」
現在、科学研究費補助金によりOxford Advanced Learner’s DictionaryやLongman Dictionary of Contemporary Englishに匹敵するような外国人向け日日辞典のサンプルを作成中である。進捗状況は、見出し語約28,000語、ミクロ構造サンプル500語、定義記述語彙約4,800語となっている。本発表の前半では、日日辞典の必要性、見出し語の選定、ミクロ構造、定義記述語彙リスト、作業体制と執筆マニュアルなどの概要を説明する。後半は、参加者の皆さんにも実際に単語の語義を考えていただく機会を作った上で、この日日辞典の語義記述の特徴を解説する。
Vincent Ooi先生(Department of English, Linguistics and Theatre Studies, National University of Singapore) ‘Modelling English use in Japan and Singapore for the dictionary’(英語によるご発表)
★2本とも勉強になる内容でした。日本語辞書は私も将来的に手掛けたいものですが、やはり対象と手法の選定がむつかしいなあと思いました。たとえば私がやるならコーパス準拠ということになるでしょうが、どのレベルの海外学習者を対象にするのか、そのレベルの学習者なら直接そうした情報を得られるのではないか、など、いろいろ考えます。
★ICNALEでもお世話になっているOoi先生のご講演も興味深いものです。日本語の外来語をKachruの3つの同心円モデルに載せて整理しようという試みは意欲的で意義深いものだと考えます。もっとも外来語の来歴はさまざまでなかなか3分類は難しいかもしれませんが。
ゼミのOGでもある中国湖北大学の張副教授のゼミと合同セミナーを行いました。なかなか対面では会いにくいですが、zoomがあるとこういうイベントが簡単にできていいですね。当日は、2大学のほか、華中師範大学呂衛清先生ゼミの参加もあり、26名程度の出席がありました。
2022年度 神戸大・湖北大 外国語教育学合同セミナー
日時 2022/11/11(金)日本時間1900~2100
場所 Zoom
【第1部 学生発表】
1900-1915 黄俊輝(湖北大M1)「日本語学術論文コーパスの構築とその応用例」
1915-1930 廉沢奇(神戸大M1)「学習者コーパス調査をふまえた、日本語学習者のABAB型基本オノマトペの使用実態の解明」

1930-1945 飯島真之(神戸大M1)「日本人英語学習者による英作文における英語確信度副詞使用:ICNALEの6EFL地域別頻度調査に基づいて」

1945-2000 陳迪(神戸大D1)「『多言語母語の日本語学習者横断コーパス』を用いた日本語学習者の発話における高頻度漢語動名詞使用実態の解明」

2000-2015 劉敏(湖北大M2)「N1聴解試験の妥当性についての検証」
2015-2030 質疑・講評
【第2部 教員小講演】
2030-2045 張晶鑫(湖北大副教授)「『政府工作报告』の日本語訳(『政府活動報告』)の言語特徴の解明」

2045-2100 石川慎一郎(神戸大教授)「L1日本語の動詞使用の発達を探る:JASWRICを用いた分析」(※時間が足りなくなったため、オンライン講演に切り替え)

2100-2105 閉会
表記で3人のゼミ生が発表しました。今回は初めてのポスター発表形式でしたが、インタラクションンが増えてよかったように感じました。
外国語教育コンテンツ論コース第4回集団指導
2022年10月28日(金)9:00~
開催方法:対面、D615教室
M1 飯島 真之「日本人英語学習者による英作文における英語確信度副詞使用―ICNALEの6EFL地域別頻度調査に基づいて―」
M1 廉 沢奇「学習者コーパス調査をふまえた、日本語学習者のABAB型基本オノマトペの使用実態の解明」
D1陳 迪「発話における日本語学習者の高頻度使用漢語動名詞」


・・・・・・・・
終了後、(研究生にとっては入学後1年以上たっていますが。。。)歓迎会として神戸の北野に行きました。ゼミで大学外で集まるのは、コロナの前以来なので3年半ぶりとなります。
食事のあとは、異人館散歩、北野天満宮で絵馬の奉納、その後足を延ばして元町中華街で解散とあいなりました。楽しいひと時でした。



共同研究員として参加している「多世代会話コーパスに基づく話し言葉の総合的研究」の内部研究会で発表(ショートトーク)を行いました。
10月25日 18:10〜19:10
石川慎一郎(神戸大学)「「小中高大生による日本語絵描写ストーリーライティングコーパス(JASWRIC)」に見る13年間の動詞使用の変化」

このほか、発達系の研究者の2名の発表をうかがうこともできました。異なる観点からの言語的な「発達」の見方も知ることができ、勉強になる時間でした。
最終更新日 2025/10/13
2023~2025年度 科研(基盤B)「ICNALE WE22構築」(23H00641) 進捗報告
◎このエントリの位置付け
本エントリは,報告書「科学研究における健全性の向上について」(日本学術会議,2015年3月6日)の(2)-1および(2)-5アで指摘されている「研究ノート」の電子版として位置付けています。その都度の準備の状況・実験の過程・問題点などを時系列的に記録し,誤記の修正などを除き,過去の内容は変更しないこととします。
◎事業目的(2024/4/1現在)
(1) ICNALE WEをアジア圏のデータ未収集国に広げ、アジアにおけるカバー率の上昇を目指す。
(2) 幅広いEFL/ESL圏学習者の作文を計量的に分析し、L1影響や地域影響の実相を科学的に解明する。
(3) あわせて日本人L2英語産出の多面的分析を可能にするため、L1/L2日本語にかかわる幅広いデータの収集と分析を行う。
◎事業経緯
旧科研(2020~2022年度、基盤B)の末期にミャンマーでのデータ収集ができる可能性が生じ、旧科研のサブプロジェクトBとしてミャンマーでのデータ収集事業を開始。しかし、政変による状況の不安定さのため、協力者が離脱し、2022年度中でのデータは白紙になる。事業は新科研に継続。
◎2023年度(1年目)の実績
過去の研究で十分なデータが取れていなかった9か国で新たに527件のデータを収集した。また、既存のICNALEデータのメンテナンスを実施した(WEのタグ付け修正、GRAのファイルアップデート)。あわせて、2024/2/3に国際シンポLCSAW6を開催した。
◎2024年度(2年目)の目標
アジア圏国際英語学習者コーパスICNALEは世界で広く活用されているが、カバーされている国は10か国・地域にとどまる。本研究課題は新たに10か国以上で作文収集を行い、データのカバレージの向上を目指す。あわせて、研究の中心対象となる日本人英語学習者のL2産出の特性を多元的に解明するため、比較用のL1日本語データおよびL2日本語学習者データの収集と分析を実施する。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
【収集の記録】
●2023年4月開始時点(目標)
重点地域(100名) Cambodia, India, Malaysia, Vietnam
その他10地域(50名) Bangladesh, Bhutan, Brunei, East Timor, Laos, Maldives, Mongol, Myanmar, Nepal, Sri Lanka
※合計400+500=900
●2023年8月現在 394人(BGD, IND, LAO, KHM, MMR, (MNG), MYS)
●2024年1月現在 527人(LCA、VNM)
●2024年10月現在 627人+α(BRN、VNMを追加) V0.3リリース
●2025年5月現在 757人(IND、VNMを追加)
●2025年6月現在 851人(NPLを追加) V0.4リリース
●2025年7月現在 948人(VNMを追加)V0.5リリース

~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
●2024年度データ収集計画と進捗
VNM Pham Quy (Ton Duc Thang U) 8/17: 50 completed
BRU Zayani Abidin (U Brunei Damssalaw) Completed
_________________________________________
2025/1以降
VNM Hien, Hoang Thi Thu (Quy Nhom U) ☛2025/2に督促するが返事なし
IND Sirigirajo Meekakshi (IIT) 2025/2/4 ☛14/23採用
●2025年度データ収集計画と進捗
(終了)
VNM :Loan Nhị Hà Ha (University of Economics - Ho Chi Minh City, PhD candidate) plans to collect 50 ☛最終63
IND:K. Venu Madhavi (The English and Foreign Languages University, Hyderabad, India.)
Udaya Muthyala (The English and Foreign Languages University, Hyderabad, India)
Pusuluri Sreehari (The English and Foreign Languages University, Hyderabad, India)
Lalitha Bai (Vignan Jyothi Institute of Technology, Hyderabad, India) ☛ 最終64/125
NPL: Krishna collect 50 ☛最終50/80
VNM Cao Hong (Vietnam Matima U) 97/121
(予定)
VNM:Dinh Thi Mai Anh (Nottingham Trent University/Vinh University) plans to collect 50 [Dec 2025] ※6月コンタクトあり。7月コンタクトあり。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
【月次進捗】
2025年度
【10月】
・ネパール学会発表準備。
・WEPのマージファイルにファイル名不正の者が混じっていたことに気づき修正対応
・あわせてUTF-8になっていることについても再度チェック
・Springer用の原稿(SMベース)を提出
【8-9月】
・ベトナムより新規データ収集にかかる調整
【7月】
7/1 VNM追加データの検証
7/2 VNM Cao Hong氏のデータの検証結果の告知、支払い準備
7/4 出金処理
7/6 データ整形・チェック、V0.4リリース、EJTKANの発表申し込み
7/10 言語資源WS採択
7/14 EJTKAN修正版が届く(開発版v0.2)

7/17 会計処理手続きの開始、学習者コーパス研究会の発表の概要送付
7/19 EJTKAN論文執筆開始。LLRの正負が混ざっていることに気づき修正のリクエスト。
7/29 ベトナムからデータ収集の照会。
【6月】
6/8 Nepal データのチェック
6/9 Nepalデータの最終受付、チェック追加
6/10 公開用データ整理、participant survey sheetを本体に結合
6/11 WEPの関係者リストの整理、公開準備、公開完了。ウェブサイトの微修正。ベトナムに督促→反応あり。
6/26 EJTKANのネーミングを決定、国語研WSに申し込み、サイト修正依頼を発送
【5月】
・5/8 特徴語自動抽出システムの出力サンプルを受け取り
・5/11 ネパールから65人分
・5/24 特徴語システムのフィードバックを返送
・Raysonの出力に2つを加えてもらえるよう依頼。LLRはランカスターとPaul Raysonの値があわない。。。
・5/28 JASELEの予稿集原稿に最新のデータを入れるべく、WEPデータの整理開始、システム開発からのフィードバック、WEのKORのduplicationの連絡あり、ネパールに督促・返事あり、データ整理継続中。
・5/28 システム開発、検算ファイルが届く。
・5/29 往復東京出張中の新幹線の全時間を投入して、インドデータをエクセルから切り出し。作文テキストもないので一から作業に。5時間と少しでおよそ終わる。
・5/30 ベトナムデータの属性データの取り出し。マージファイル作成。PTJ/SMKのスワップチェック。
・5/31 上記修了。ほぼ出せるところまできたが、まだネパールの最終データが届かずどうしようかと悩む。このままV0.4で出すか、待つか。
【4月】
・4/22 インドデータとベトナムデータのveririficationが終わりベトナムは会計処理へ
・4/21 インドより二次データ納品
・4/18 新検索システム開発について要望を伝達(LLRとeffect sizeの計算式の確定)
・4/14 ベトナムデータ納品
・4/13 インドよりデータ納品(1次)
・4/11 新検索システム開発について先方より返信あり
・4/21 インドより1次の追加
・4/22 インドにチェック結果を返信、ベトナムの送金手続き指示
・4/23 インドより2次
・4/25インドより1次の差し替え
・4/29 インド追加データのverification。インドの最終数確定支払い指示。
・4/30 インドの追加データを含めて最終verification。数を確定して再度支払い指示へ。
2024年度
【3月】
・3/10 ベトナムの教員と新規データ収集にかかるミーティング
【2月】
・ThaiTESOL参加者へのリクルーティングでベトナム・ネパール・インドの協力者が決まり、2/4に、順次、zoomで説明会を実施。
・2/4 本年度計画のVNMとINDの協力者に進捗照会。
・2/4 3件のzoomミーティングを実施
・2/5 IND Meekakshiよりデータ(23)を受け取り
【1月】
・Thai TESOLでWEP研究を発表。会場で協力者をリクルーティング。
・JASWRIC論文、LEARNジャーナル論文が正式に公開。
【11-12月】
・WEPデータで論文執筆、LEARNジャーナルに投稿→修正採択。
【10月】
・Agdeppa氏納品データ(4~9月を整理)、データを増やしてV0.3として公開(※V0.2としては公開されていなかったので、新規にV0.3として公開。ファイル名をWE2→WEPに)
・上記に伴う会計処理
・上記に伴うHPメンテナンス
【9月】
論文執筆・投稿
・小中高大生の作文に見る動詞使用パタンの変化――JASWRICの「鍵」作文の分析―― (27p)☛改稿・受理
・ICNALE WEPlus V0.2の加工
・Reconsideration of L1 Effects on Asian Learners’ L2 English Writing: A Study Based on the ICNALE ☛新規投稿(V0.2に基づく)
【8月】
新年度~8/16までに脱稿(投稿、投稿待ち、改稿中)した論文のメモ
・中間言語対照分析(CIA)のためのI-JASダウンロードデータの加工―I-JAS for CIAの整備―(23p) ☛言語資源WS
・English/Japanese Word Frequency Table Generator(EJWFTG)を用いた日本語統合語彙頻度表の作成と活用(10p)☛計量国語学
・日本語学術論文の即時オープンアクセス実現に向けて(26p)☛国語研論集
・小中高大生の作文に見る動詞使用パタンの変化――JASWRICの「鍵」作文の分析―― (27p)☛改稿中
8/17 VNM Quy氏より2nd batch 28本が到着。同日内容チェック、事務に支払い手続きを依頼。
8/25 全国英語教育学会(JASELE)でICNALE WE22の内容について報告。
8/27 Quy氏よりSDのビデオのデータ不備2点の指摘を受け、元データにアクセスし、音声ファイルを復元し、アップロード。ICNALEサイトに修正告知を出す。こうした意見を付けてくれる人がいるおかげでデータのミスが直っていく。感謝。
【7月】
7/9 VNM Quyチームより1st batch 22本が到着。
【6月】
6/1 北京とのシンポについて広報業務がいちおうかたがつく。
6/2 国語研用の論文修正を進める。対応分析は上位40語だったが、それだとクラスターと同じだと思いなおし、100語でやり直す。情報量が倍増していい感じになった。また、元の版にあったL2との比較はトピック統制がなされていないこともありカット。
6/9 締め切り1日前になんとか提出。
6/12 計量国語の依頼原稿に着手。
【5月】
5/1 仮にWE2と命名(※本体のWEに組み込まない)
・データの整形、rename作業
・フォルダごとにデータを作成
・10件以上のデータについてのみマージファイルを作成
・POSタグ付け(Sketch Engineだと20個送っても1つにまとまってしまうので、今回はTagAnt使用)
5/2 サイトアップデート、ダウンロード対応、プルダウンにWE2を追加。
・初年度で500名、1000件のデータがリリースできた(参加者総数が5000人を突破)

【4月】
4/1 新年度事業開始
4/3 新年度交付申請書の作成
4/19 新年度交付申請、支払い請求が学振で受理
4/19 過年度の収集実績の確認、本ブログのデータの整理
4/23 カナダの仲介者に新年度のデータ収集依頼
___________________
Brunei 50 (新?)
...................................
India 15 (85に追加)
Laos 15 (35に追加)
Myanmar 18 (132に追加)
____________________
4/29 初年度収集データの整理作業開始
・台帳整理(stage 2をstage 1台帳に統合) ※仮コードのMMR/MYMのブレを修正
・コードをacceptデータのみで新しく振り直し
・VSTのスコア計算、動機付け指標など計算、公開準備用属性ファイル準備完了
4/30 事務に2024年度のデータ収集について仕様書のチェックを依頼
(参考:単価見積の記録として)

2023年度
【3月】
3/30 AsiaTEFL用論文査読対応、再提出
【2月】
2/5 謝金の着金完了
【1月】
1/8 Stage2データ提出サイトをクローズ。検証準備。
1/9 エクセルからテキストファイルを作成・命名。検証作業開始。
1/10 Stage2の検証終了。結果を仲介者に通知、会計に支払い依頼。延長申請の文章を下書き、事務に添削を依頼。仲介者に協力者別の採択数を通知。
1/12 事務より作業者に謝金支払い準備の連絡。
1/13 上記の会計システム登録を完了。
【12月】
12/5 事務より仲介者に契約書サイン依頼
12/11 修正して再送
12/18 督促
12/20 上記対応あり
【11月】
11/1 会計より契約仕様書作成依頼
11/6 頻度データ処理システムの見積もり依頼
11/7 同上詳細情報を送信
11/8 仕様書のアップデートを行い事務に提出。現状を確認(インド77、ベトナム6,スリランカ4)。仲介者に状況シェア。
11/15 オンラインシステムへのアクセスにかかる照会あり、下限照会あり
11/21 下限について指示あり
11/23 仲介者よりインドデータのチェック依頼
11/24 対面で意見調整(部局決裁可能な範囲まで下限を下げて仕様出すことに)。現時点で集まっているデータの整理、テキスト化まで終了。
11/26 チェック終了、仲介者にフィードバック
現状確認
★インド 23+56=79 (+21目標)
★スリランカ3, ベトナム6は今年度の追加は困難
★Stage2はじまりのブルネイとネパールはまだ未収集。ミャンマーは+11目標だが、こちらも未収集か?
★Stage 2は現状88本受領。年末までに100いくか?
11/29 新仕様書チェック済
【10月】
10/2 送金完了
10/6 投稿用論文の修正作業を再開(※5月に書いていたもの)
10/9 第2期依頼についてSecond priority諸国でのリクルーティングが難しいとの連絡あり。リクルーティング終了後再度相談することに。
10/11 投稿用論文を英文プルーフに出す
10/17 戻り原稿のチェックを開始
10/20 作業者と現状確認およびStage 2計画の詳細を確認
10/24 原稿のチェックを再開。3.1.3(地域比較)の内容がしょぼかったのでこの個所全面的に改訂。
10/28 後半いろいろ触って、投稿完了。
【9月】
9/13 第1期の送金作業
【8月】
8/4 KHM、BGDより追加データ送付あり
8/8 KHM、BGDの追加データのテキスト切り出し、重複チェックを開始するが、これまでの総体における重複見直しがありうるのでまとめて再チェックにかける
8/10-11 再チェックが終了。残ったデータを悉皆で語数計算。基準以下のものを棄却。最終的に408人を採用、362人を棄却。基本方針<2~3語レベルではなく10~15語スパン(KWICの一方のコンテキスト>で完全一致または酷似が認められたものを棄却。似た内容、表現があるが英語の単語選択などが一致していないものは、外部資料参考の可能性があっても自分なりの書き換えがなされていると判断して採用。コピーの時に入り込んだ「"」を一括で削除、「'」を上書きで置換。
8/12-15 Survey dataのチェック。個票から張り付けるのだが予想以上に面倒で時間がかかる。作業過程で高校生データ混入と、L1中国語学生?データの混入を確認。仲介者に確認依頼。
8/16 Vocテストスコアと、学習経歴アンケートの自動計算。
8/19 カナダでとったインド人追加データ到着。
8/19 Stage 2 計画の相談
8/22 インド追加到着
8/25 マレーシア追加到着
8/27-28 追加分含めての再検証。rejectが発生。
8/29 最終版として394、事務に報告、検収依頼。
8/29 Stage 2のためにGoogle Formを作成。剽窃しないよう重ねての忠告を行う。仲介者にGoogle Formを伝達。IND129→BDG165の修正対応。

【7月】
7/5 マレーシアから先行取得データが届く。1週間程度で検証の予定。作業手順の確認。
テキストファイル化→語数チェック→トピック間違い確認
7/6 バングラから先行取得データが届く。バングラは既存のコーパス研究ではほとんどカバーされておらず価値あるデータ。
7/9 別件の講演準備が終わりデータ処理に着手。まずエクセルのファイルタイプを連番変換。バングラ94件の作業を開始。
7/10 バングラ分、テキスト化→属性情報の集約化まで終わる。
PTJ 25144語 SMK 24414語
DupFileEliminatorを導入。バイナリレベルでテキストの重複を確認
検証:PTJ smoking, always, think, firstly, really, tuition, working
検証:SMK sometimes/usually/often/think/all/around/breathe/clean/air
検証:survey/VST(合計とSDで重複を検出)
=======================
エッセイ重複疑 21/30/42/62/79
アンケート重複疑
44/75, 21/42/62/79, 20/48, 36/54/88, 32/61, 71/91
→学生にやり直しを指示
=========================
リエゾンにフィードバック結果を送信。
7/11 リエゾンより最新状況の報告。調整案を提案。マレーシアのテキスト化。
7/12 丸1日かけて、インドのテキスト化と属性データの台帳転記終了。time-consuming。。。 後はマレーシアの属性転記だが、明日終わるか。。。
7/13 Malayの転記終了。段々慣れてきた! ちょっとほかの仕事をやる。
7/14 ばらばら検証をやりかけていたが、再度一から見直したくなり、BGG/IND/MYSの全ファイルを一括フォルダに集約し、1)DupFile Eliminatorと、MATの全標識数値の統合値の2観点で重複を機械的に抽出。エッセイの完全重複の認められたインドの42名/121名、タスク未了のマレーシアの2名/113名をreject決定。リエゾンにフィードバック
==========================
1) X Malaysia
Aim: 70 Collected: 70 Accpted:68 Rejected:2 (Half done)
2) Y Malaysia
Aim: 30 Collected: 43 Accepted: 43
3) Z India
Aim: 90 Collected: 121 Accepted: 79 Rejected: 42 (Essay duplications)
===========================
7/15 カンボジア、ミャンマー、ラオスのデータが到着。
7/16 カンボジアとミャンマーのテキスト化が終了。
7/17 インドの2つ目のデータは重複が多く受領できないと判断
7/18 検証済みのものも含めて再度KWICで重複の検査。予想以上に類似が多く、フィードバックをリエゾンに出す。この作業は教師の心をむしばむ。学生の不正行為?を探すのは心が折れる。しかし、テストでもないのに、なぜ自分の力でできる範囲で書かないのだろうか?? 仲介者にFeedbackを送信
7/19 仲介者より自分でも検証をしたいという要望→手順を説明してむつかしいことを伝達
7/19 不採択にしたインド教員よりクレームあり、仲介者が対応
7/19 長さ、剽窃なし、について再度仲介者に説明
7/20 事務より回答(現在契約中で、数が不足したらについてはこの段階では回答できない)
7/20 事務より受け取り拒否できないという回答、同日、石川より事情説明(提出→検証→最終受理)、これには返事なし
7/25 日本語版にはなかった(もともとはあった)報酬規程が英語版で加わっていることについて照会(この過程で金額が変更されていることがわかり、石川より事務に確認を依頼)
7/26 回答:金額は(石川の承認なしに)交渉で変更、データ数は条件を満たしていなければ契約を下回ることはありうる→石川返信、なぜ金額変更?もともと日本語になった金額が消えているのはなぜ?(再度翻訳する必要はなかった)、条件に満たないものは受け取れない、という理解であっているか?
7/26 Clear 50の意味の問い合わせ、reject氏名の要望
7/27 仲介者に返信、ミャンマー、カンボジアデータ受領
7/28 コードの割り振り表を送付、あわせて期限延長について 再度英語で事務と仲介者に同時メール発出・・・この数週間、かなりストレスフルな仕事の環境になっている。私、仲介者、実際の教員、学生、大学の担当部署、大学のその上の上部部署の間で、ぐるぐる話がまわって段々相互誤解が生まれる。なんとかならんかなあ。
7/29 新規データのテキストファイル化。
7/30 データの重複と剽窃をチェック。仲介者にフィードバック。採択率は約50%。
【6月】
6/8 修正版仕様書を提出。その後、データ収集に関する会計処理で事務との見解の相違が発生。直接面会して対応を協議。
6/20 仕様書の英語版を要請され作成して送付。
6/30 ICNALEベースシステムのアップデートが完了。フォルダ構成やファイルネームなどモジュール間で不統一であった個所が改善された(はず)。GRAはデータ待ちだがそれ以外は202306バージョンとして更新完了。
【5月】
5/8 Poland論文について、Dimension scoreを表でなくグラフで表示する方向に転換、dimensionごとのloadの強いfeatureの情報を記載
5/8 データ収集用にGoogle Formで語数設定をかける技術を習得
5/9 Poland論文のデータの不整合が気になり始め、タイのB2を入れて分析をやり直しすることに。ESLを抜く、EFLは全部入れる、keywordはLLではなく%で抽出する方針に転換
5/9 データ収集の可能性を含めて、講演を依頼してきたマレーシアの大学教員に連絡
5/10 講演日程確定
5/14 ぎりぎりになったが、SSLLT (Kalisz)用の分析が完了(論文)、パワポも一応完成。
5/15-17 SSLLT2023で研究発表
5/22 海外協力者に参画意向を打診、返信あり。エクセルのデータ収集フォームを微修正。学年などは入力ではなく選択方式に。テストには満点表示。語数の自動計算も追加。


5/23 GRAを含めた検索系の改修・新設について業者に見積もり依頼を行う。あわせてGRAに基づくベンチマーク自動抽出システムの概要を考案し、資料にまとめる

【4月】
4/1 新年度スタート
4/3 AsiaTEFL2023より採択通知、年会費支払い
4/5 科研システムより受領申請手続き、仕様書を作成、事務に確認依頼【事業開始前の動き】
4/6 事務と相談し、積算根拠を確認
4/24 Poland学会用のエッセイ分析開始
4/27 インドネシアの共同研究者に参画の可能性を打診(→可能性うすそう)
~~~~~~~~~~~~~~~~~~~~~~
2023年度特別事業1(LCSAW関連 ※旧科研)
(2024年2月)
2/2 事前打ち合わせ
2/3 シンポ実施
2/17 websiteを更新(記録写真のアップ)
(2024年1月)
1/5 一般公募の締め切り(予想外に集まってよかった)
1/5 招待発表者への口座登録依頼
1/6 会場本予約、採択通知の発出
1/8 プログラムv1の作成、チェック依頼
1/8 ウェブサイトの更新(LCSAW5の情報追加)
1/9 プログラム最終版の作成、MLでの告知、ウェブサイトの修正
1/10 ウェブサイトからのProceedingsリンクの修正、海外招待発表者への招聘状送付、Promisへの後援依頼、情報センターにビジターLANアカウント発給依頼、参加申し込みサイトに「対面のみ」である注記を追加
1/13 発表者で申し込みのない人に督促(1/12期限だったもの)
(2023年12月)
12/20 やるかどうか迷っていたが、思い立って発表募集告知を発出(here)
12/20 招待発表者への意向伺い
12/29 招待発表者の追加
(2023年11月)
11/6 会場だけ仮予約
(2024年2月)
2/14 オンラインシステムの整備状況を照会→月末まで予定
(2024年1月)
1/2 SEより返信
My senior colleagues insisted that they were not 100% sure, but very probably this option (selection of different part-of-speech tagsets for user English corpora) was not publicly available in the interface. If so, we cannot provide this tagset for tagging due to licensing.(古い社員に聞いてもはっきりしないが、たぶん、タグの選択システムは一般には公開していなかったはず)でも使ったのに。。。。
1/4 アイライトに連絡。新タグで統一の方向を連絡。
1/5 アイライト返信あり。FTPアカウント情報が必要、新タグでは3列全てのデータが必要とのこと。同日FTPアカウントデータを提供。
1/11 1/12 匿名化漏れのチェック、大学名の残存を数点確認→対応。
1/13 Antconcに全体ファイルを読み込む際に2つでエンコードエラーを検出→修正。前回のマージ作業では、並べ替えが効いておらず、その後に匿名化による内容変更が起こったため、再度マージ作業を一からやりなおし。Text Join作業で、すべてにおいてソートのプロセスを組み込み。Sketch Engineで全体を新タグでタグ付け(Tree Tagger v3.3)。あわせてアイライト向けに作業の詳細解説ビデオを作成、業者に送付。
(2023年12月)
12/22 業者(アイライト)にOnlineのシステム落ちへの対応を依頼。あわせて、JFICの作業開始を指示。あわせてWEについてはコードの違いを示し、タグ付け後のvertの3列データのどの部分を使っているのか照会。
12/22 利用者からの意見にもとづき、WE2.5のタグセットのチェック開始
=====================
CHN A2 PTJ
ENS XX2 PTJ+SMK
ENS XX3 PTJ
======================
AntconcでI-dをキーとして全vertデータを検証。上記4種のvert dataのみ、タグセットが他と異なっていることを確認。
他全部:I-p, really-r
4セット:I-d, really-a
Sketch Engine(expiresしていたので再入会)でデフォルトのtree tagger3(ceecusptjでも同じになる)で処理したところ、以下を確認。
◎旧タグ(CHN_B1 PTJ)
I PP I-p 代名詞はp
think VVP think-v
a DT a-x 冠詞はx
part NN part-n
time NN time-n
job NN job-n
is VBZ be-v
one CD one-m
of IN of-i 前置詞はi
the DT the-x
most RBS most-r 副詞はr
important JJ important-j 形容詞はj
things NNS thing-n
in IN in-i
college NN college-n
life NN life-n
<g/>
◎配布版の4ファイルのタグ
I PP I-d 代名詞がpでなくd
agree VVP agree-v
that IN/that that-i 前置詞と同等扱い
it PP it-d ここは変更なし
is VBZ be-v ここは変更なし
important JJ important-j ここは変更なし
・・・
Thus RB thus-a 副詞はa

12/23 Sketch Engineより返信あり。In this tagset, the pronouns are tagged with a tag starting "P", and thus the lempos suffix is "-p" instead of "-d". This part-of-speech tagset is available only for corpora annotated outside of Sketch Engine.Tree Taggerのタグとしては変わっておらず、もしpがつくならCLAWSでは?とのこと。CLAWSが使えるのはWmatrixで、たしかにそれも昔使っていた記憶もあるので、作業したのはWmatrixだったのだろうか・・? しかし、Sketch Engine側にCEECUSなど、10年前に自分が処理したコーパスの名称が残っているので、やはりSketch Engineで付けたのではないかと思われる。記憶があいまい。。。ともあれ、ダメな場合は、lempo(レマ+POS)だけ手作業で代えるか。。。
12/23 Wmatrixのアカウントが発給されたが明らかにデータの形式が違った。やはりSEだったと確認。

12/23 SEに対して外部ではなくSEでそうしたタグができたことを主張するが話が通じない(新しく入ったスタッフ?)。Wmatrixを使った可能性もあるかとこちらで考え直す。Wmatrixのアカウント取得して実験するが同じようにはならない。やはりSEだろう。
12/24 業者から返信あり。サーバーダウンは解消したとのこと。Braveではシールド外さないとうまくいかないみたい。(前はいけたのに)
12/24 アイライトより返信。画面ブランク問題については、http"s"がつくと落ちる、ことを確認。石川サーバにアクセス不可とのこと。
(2023年10月)
10/28 ユーザーより連絡。マージファイルの中国A2のタグが他とずれているとの指摘。次期版で修正するよう回答。
----------------------------------
---2023---
1/11 ミャンマー担当教員が事情で収集困難になったとの通知(※本年度の収集は断念)2/28 新科研の採択が内示
---2022---
9/28 次期科研としてICNALE-WE22プランを策定して申請
10/16 インドネシア協力者よりミャンマーでのデータ収集予定について問い合わせ
10/17 新プロジェクトへの招聘
10/20 参加教員の承認11/3 協力者より紹介メール、参加教員の連絡先確定(Nan Ingyin Phyu)
11/6 こちらから着信確認
11/14 プロトコルブック修正、エクセル再修正、先方連絡、謝金修正(円安反映による20%増額)、今の状況下で200人は厳しいので100人目標でという返信(了承)→収集開始。
表記がオンライン開催され、参加しました。
今回の理事会では、私が前の会で提案した紀要の「、。」化が審議されましたが、大勢は時期尚早という意向でした。
この問題はどれが正解なのか、文化庁が絶対基準なのか、いろいろ考えるべき点があり、それによって結論も変わってきますが、表記は日本語学では大事な研究テーマでもあり、少なくとも、この点について「気にしておく」ことだけは必要かなと思います。
個人的には、MS-IMEを「、。」にしてから句読点が一気に変わってしまいましたが、日本語文中に英語を出すときなどは面倒なのも確かで、いろいろと悩ましい話ではあります。
言語系の学会であれば、どこであっても、またどの方針を取るにせよ、句読点に関して、HPの表記、学会のおしらせなどの表記、規約などの表記、論集のテンプレートの表記の統一は、今後考えてもいいかもしれません。これは日本語のみならず、英語系でもしかりでしょう。
表記で、新指導要領に基づく新しい観点別評価の理論と実践についてお話ししました。

小中と同様、学びに向かう態度の評価は難しいところですが、粘り強さと自己調整、また、態度と他の2観点がそれぞれ連動するとされているので、過度に態度評価だけを独立的にとらえて悩む必要はないと思われます。同じものを念のために3つの窓からのぞいてみる、1つの窓から覗くだけでも十分かもしれないが、念のために別の窓からものぞいてみる、こういうイメージが重要だと思われます。
講演後、帰りの電車で漠然と考えていた概念図です。言いたいこと、伝わっているかなあ?

尼崎は、数年前、観点別評価導入や新しい道徳の導入の時に、小学校・中学校をたくさん回った地域なので、久々の再訪、嬉しかったです。
表記で特別講演を行いました。
特別講演
石川慎一郎(神戸大学)
「日本のこどもがI-JASのSWをやってみた! ーJASWRICの概要と研究応用について-」
(概要)
講演は3部にわけて行います。第1部では、I-JASのSW課題を使って構築したJASWRICという新しいコーパスの概要をご紹介します(30分程度)。第2部では、気分転換(?)を兼ねて、I-JASとJASWRICの比較分析を行うのに必要な、<統計的特徴語分析>のやり方について、実践ワークショップを行います(30~60分程度、様子を見て)。最後に、第3部では、第2部で扱った技術を用いてI-JASとJASWRICを連動分析した研究の結果についてご報告します(30分程度)。

表記で招待講演を担当しました。

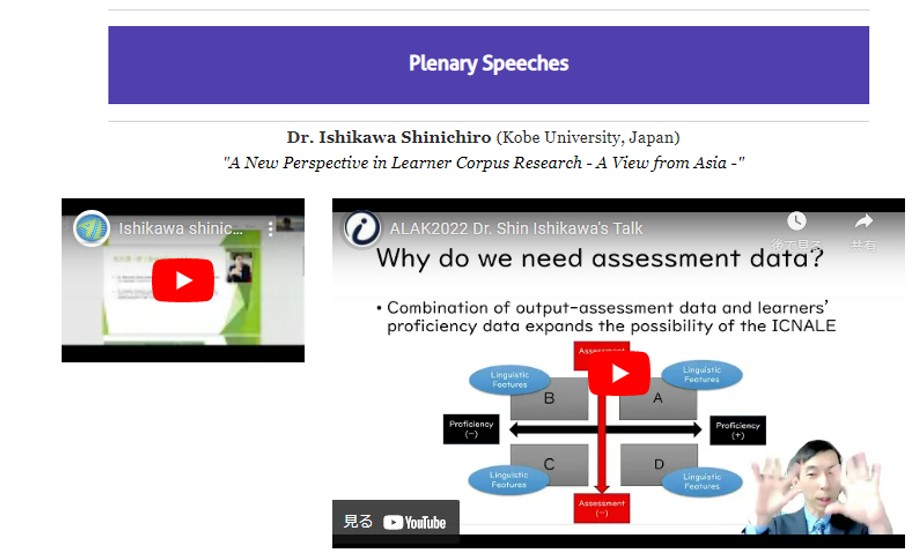

オンラインベースでしたが、大変組織された運営で、いろいろ感心しました。ICNALEの国際チームの一員でもあるTecnam Yoon先生の、いつもながらのすばらしい運営に感謝。
表記に参加し、特別シンポの司会を担当しました。
シンポでは、学習者コーパス研究において多元的なコーパス準拠モデルの使用を提唱しておられるGilquin氏と、ELFの立場からモデルの問題に別視点を持つPitzl氏をお招きし、それぞれの見解を語っていただきました。
異なる立場のぶつかり合いの中から、参加者は、それぞれが、自身の研究や教育で用いるモデルの形を考えるきっかけを得たのではないかと思います(少なくとも私はそうでした)。二名の講師に加え、大変刺激的なな企画を立案された名城大の藤原先生に深く御礼申し上げます。
個人的には、なぜともかくも通用しているのに、あえてそれをanalyseしないといけないのだ、compareしないといけないのだ、というPitzl氏の指摘がこたえました。これに対するはっきり答えを持つようにしないと、学習者コーパス研究のさらなる展開はむつかしいなあと再確認した次第です。比較は科学研究の基本だろう、という反論だけではいかにも弱いと思われます。この点、自分でももう少し考えてみます。
パワーポイントを使って講義ビデオを作ることが増えましたが、60分や90分話し終えて、ビデオにしてから、元のパワーポイントの誤植を見つけることが時にあります。この場合、動画は触れませんので、修正が効かず、撮り直しとなると大変です。
動画加工ソフトで、「字幕」とか「タイトル入れ」というような機能を使えばなんとかなるのではと感じたのですが、そもそも趣旨が違うので、ほしい情報がありませんでした。
やりたいこと
→ ビデオ内に、一定時間表示されるパワポ画面(白背景、黒文字)の中の、特定の文字・語だけを、正しいものに置き換える(あるいは上に正しい文字・語をかぶせてしまう)
やり方、さんざん調べてもよくわからなかったのですが、さわっているとなんとなくできたので、自分メモとして記録します。
2023/1/10 追記(version upのため)
使用ソフト Wondershare社のFilmora(サイト)※ライセンス購入済み
1. 新規プロジェクト→ビデオをソフトに読み込む
2. 画面左上に表示されるビデオのアイコンを、左端によせながら、下の段にドラッグして移す。その際左端に落とし込むようにする。
3. 修正をいれたい箇所あたりを再生する
3. ソフトの画面上部にある「T](タイトル)のアイコンをクリック。各種のタイトルから好きなものを選び(※どうせ使わないのでなんでもよい)、下部画面(コマ写真がずらっと横に並んでいるもの)の、修正を入れたいコマの1コマ目の上あたりにドラッグしていれる。メインビデオの列に挿入するのではなく、その上の列に入れる(2列にする)
4. 下部画面、2列目に入ったタイトルアイコンをダブルクリック。ウィンドウの右下に出て来る「高度編集」を押す
5. 新しい画面が登場
6.3で仮に入れたものを削除
7. 画面の上部、テキスト(T+)の横のにある図形挿入のアイコンを押す
8. 長方形を選んで(デフォはグレー地に白文字)、誤植文字列にかぶせるように移動
9. ダブルクリックで文字を修正後の正しい文字に変更
10.デフォは白文字なので、ぬりつぶし→色のぬりつぶし で文字色を黒に変更
11. 文字塗りつぶし、不透明度・・・などの一番下までスクロール
12. 図形ぬりつぶしのグレーを白に変更(これで白背景、黒文字になる)
13. 画面の一番上、B 、I の横にあるボタンで図形内で左寄せに移動
14. OK (高度編集画面上では、どこからどこまでに効果を掛けるかの設定は不要)
15. メイン画面に戻る
16. 画面下部にある、追加図形の長方形の右端を伸ばしたいところまでのばす
17. OK
18. メイン画面の上部右端にある緑色の「エクスポート」を押す
19 完成・・・だけれど、2回実験した結果、元のファイルサイズが10倍程度に巨大化する。。。
表記で、生徒さん向けの探究入門講義を行いました。
「高校探究の目指す地平:稲園版探究プログラムのために」

過去数年にわたっていろいろな学校を見てきましたが、このK点を超えられるかどうかは、かける時間とかなり正確に比例するようです。早めのスタート、早めの予備実験、早めの中間報告、早めの(時に辛口の)フィードバックがそろえば、探究が面白くなる地平に必ずや到達すると思います。稲園のみなさんにも、ぜひ、がんばっていただきたいです。
表記で、生徒さんの発表を拝聴し、講話を行いました。


この点に関して、仮にリラックスするとα波が出るという仮説を前提にするなら、α波を計測することができますし、実験機器などがなくてそれは難しいということであれば、たとえば、リラックスの反対を考え、ストレスがかかっているとうまくできなくなるような作業課題(少し難しい目の暗算問題など)を与え、そのパフォーマンスを測ることで、間接的にリラックス度(というか、より厳密に言えば「作業を安定的に行うための精神的安定の度合」)を測るといったことができそうです。もとより完璧な答えはないのですが、関心対象が直接測れない場合は、似たものに置き換えて測ったり、あるいは概念を裏返して、裏から迫ったり、なんとかして、当該の対象にアクセスすることが必要で、研究のオリジナリティはこの辺に出て来るものだと思います。
甲北のみなさんの探究の更なる発展を願っています!
表記大会で口頭発表を行いました。
石川慎一郎(神戸大) L2日本語学習者を対象とした中間言語対照分析における参照基準の拡張―「多言語母語の日本語学習者横断コーパス」(I-JAS)と「小中高大生による日本語絵描写ストーリーライティングコーパス」(JASWRIC)の連動分析の試み―

概要
本研究は,2 種の日本語母語話者(JNS)によるL1 産出データを比較することで,学習者コーパス研究(learner corpus research:LCR)における母語話者(NS)参照基準の問題を再考しようとするものである.LCR においては,中間言語対照分析(contrastive interlanguage analysis:CIA)(Granger, 1996)の手法が広く実践されている.これは,学習者間比較と,NS・学習者間比較(L1/L2 比較)の2 種で構成される.CIA は多くの成果を挙げてきたが,CIA が少量のNS データに依存していることは,NS 産出の質のばらつき・NS 多様性への配慮の欠如・誤った NS アイデンティティの強要・NS 主義への加担等の点から厳しく批判されており(Leech, 1998; Larsen-Freeman, 2014; Holliday, 2006),改訂版 CIA ではNS データにおける言語使用域や地域変種の多様性への配慮が示された(Granger,2015)。また,「全てを支配する単一基準」に代わる多様な参照データの必要性も模索されている(Gilquin, 2022).
本研究では,JNS 成人と,JNS 小中高大生による同一タスクに基づくL1 作文を比較し,その言語的差異を明らかにするとともに,2 種の JNS データを CIA の参照基準に選択した場合に,学習者の特徴語抽出にどのような影響が生じるかを概観する.
※参加者は約65名程度。当日の発表では、理念的背景というか、学習者コーパス研究におけるモデルをめぐる最近の議論について整理をしたうえで、JASWRICというコーパスの可能性を議論しました。質疑ではNSの大人の多様性にも配慮すればよいのでは、とくに高齢者の産出にも史料価値がある、というコメントをいただきました。多世代データという論点になっていくものと思いますが、高齢者の産出などはなかなか集めるのが大変そうで、このあたりも方法論的に可能かどうか検討してみたいと思います。さっそく、その日のうちに市内の老人ホームにコンタクトを取ってみました(まあ、なかなか良い返事は期待できないでしょうが…)。口頭発表の良さは、質疑やそれをふまえた内省から、次の研究のヒントが得られることだと再確認できた学会参加でした。
表記で1年生対象の探究入門の講演を行いました。
演題:高校生のための探究入門:AI時代を生き抜く力

SDGをテーマにということでしたので、内容をその方向に修正して講演資料としました。


今日は3つの学会が重なっていたのですが、zoom学会の恩恵というべきか、(主催の方には申し訳ないのですが)自分の関心に近いものを選んで聴講させていただきました。
講演 曹大峰先生(北京外国語大学教授) 北京時間(10:30-11:35)
「中日対訳コーパスの特徴とその利用方略―対訳データの利点・盲点とその利用例―」
★北京でもお世話になった曹大峰先生のご講演を久しぶりに拝聴できました。学習者産出の比較だけでなく、それぞれの原典(例えば文学作品とか)と翻訳の比較を組み合わせるべきだ、というのは、Granger/GilquinのCA/CIA統合提案と非常に似ており(というか事実上同一)、学習者研究のフレームワークのコアになりうるものだなと実感しました。こうして考えてみると、自分の研究の中で、学習者コーパス研究と、最近つくった日本語小説コーパスJFIC、日本人こども作文コーパスJASWRICという自分でもばらばら感のあるコーパスが1本の線でつながることに気づきます。この点で言うと、後必要なのは、翻訳データということになりそうです。

A07(7).小学校社会科教科書の語彙調査 ―社会科共通語彙の特徴を探る―山本裕子(愛知淑徳大学)・川村よし子(元東京国際大学)・鷲見幸美(名古屋大学)
★教科書語彙分析。専門JSPの入り口としての小学校の内容科目の教科書分析は興味深いアプローチです。英語でも「アメリカの小学校の教科書で・・・を学ぶ」のようなことがあったと思い出しつつ。
A08(8).日本語学習者・母語話者が考える多義動詞の基本的語義とは何か
大神智春(九州大学)・森田淳子(西南学院大学)・麻生迪子(四天王寺大学)・鈴木綾乃(横浜市立大学)・林富美子(明治大学)
★「ある」「きる」「でる」「つける」「する」について最も典型的だと思う意味で作文をさせ、それを分析者が語義タイプに分類するという興味深い調査。たとえば、「ある」だと、「物の存在」はNSが77%でNNSが54%でNS>NNS、一方「事の存在」は6%と11%でNNS>NSのように差が出る。手法面でもいろいろ面白いです。主要語義を書き出して典型的なものを選ばせる、3つ書かせてクラスタリングする、などほかにもいろいろできそう。
B05(22).日本語学習辞書の副詞記述に関する調査報告
関かおる(神田外語大学)・尾沼玄也(拓殖大学)・砂川有里子(筑波大学)
★「スーパーで買い物していたら(すぐ/今にも)大きな地震が起こってびっくりした」は、どちらもアウトが正解だが、NNS反応はそうでないとのこと。正直に言うと、やや不自然だが「すぐ」はありうるな、と思っていたのでいろいろ興味深かったです。AしてすぐBする、の場合、「すぐ」の前には動作の点のようなものが典型的なので、買い物をしているという状態的なものと相性が悪いのはわかりますが、なぜ自分が「すぐ」を非文とまでは感じないのかが興味深い(が今もよくわからない)。
C10(41).日本語学習者のための日常会話におけるオノマトペの語彙選定
伊藤萌夏(東京育英日本語学院)・北野朋子(関西大学)・森岡千廣(京都先端科学大学)・蔵本成美(別府溝部学園短期大学)
★ゼミ生の研究にも役立ちそう。
D05(50).中国の大学における日本語教育の変化とその対応 ―大学入試で日本語を選択する受験生を対象として―
王凌志(広州工商学院学部生)
★中国で大学入試で日本語選択をする人が増え、大学の日本語授業がやりにくくなっている(ゼロスタートでない)という報告。なるほど日本語が増えるとそうなるわけですね。英語だと小学校英語が入って中学英語の導入がやりにくくなったという話と似ていますが、受験のための日本語学習で、ガーっと知識なんかを詰め込んできた大学新入生に、また初級文法というのは確かにむつかしそうです(これ、大学の英語授業の問題ともにている)。
講演「日英語の伝統色名に見られる多様な相違」
吉村耕治 (関西外国語大学短期大学部名誉教授)
★赤ん坊とはいうが、英語のbabyには色が出てこない、なるほど!
1日に3つ出てみての感想。
1)1時間などの枠を決めて、その中でパラレルでいろいろな発表があり、人が出入りすることで、参加者は2,3個好きなものを選んで移動できるやり方(日本語教育方法)が参加者には一番ありがたい
2)予稿集はやはり紙の冊子があると便利。こういう自分のメモを取るときにも有用
3)学び、という点ではオンライン学会のほうが高いという事実がある・・・
オンライン開催された表記シンポジウムに参加しました(詳細)。
2022年度 第1回研究会 学習者言語分析Ⅰ:音声特徴と語彙特徴
日時:2022年9月8日(木)
形式:ZOOM会議による開催
13:10-13:50
日本人フランス語学習者の par exemple―学習者コーパスと母語話者コーパスの比較を通じてー
國末 薫(東京外国語大学博士後期課程)
★英語学習者のfor example過剰使用傾向とも合致する結果で興味深いです。「たとえば」というつなぎには、1)話のオンライン進行をいったんとめられる、2)単語の羅列などで、文法処理から逃げられる、3)話題を具象に強制的に落とす、などの効果があり、流暢性の欠如を補償する汎言語的な学習者傾向なのかもしれません。
13:50-14:30
フランスとカナダの留学経験者の自由会話における文化的特徴
時田 朋子(実践女子大学)、川口 裕司(東京外国語大学)
★英語留学などでは行くか行かないかは議論しても、どこに行ったからどうだったという議論はあまり聞かないので新鮮でした。
14:30-15:10
地域フランス語における談話標識bon, benの用法の一考察
清宮 貴雅(東京外国語大学博士後期課程)、
大河原 香穂(東京外国語大学博士後期課程)
川口 裕司(東京外国語大学)
15:20-16:00
フランス語を母語とする日本語学習者の日本語韻律特徴と母語話者評価への影響
布村 猛(山梨大学)
16:00-16:40
日本語を母語とする学習者によるフランス語口母音の知覚と産出:後舌狭母音/u/に関連した地域的変異による影響
神山 剛樹(パリ第8大学)
16:50-18:00
講演 日本語学概説書の翻訳から見える日本語学とフランス言語学の接点
中村 弥生(INALCO)
国語研究所で進行中に「多世代会話コーパスに基づく話し言葉の総合的研究」プロジェクトの定例研究会に参加しました(online)。
報告は3本あり、いずれも非常に刺激的なものでした。南部先生のご講演から「主語につくが・の、の交代」の歴史的変化を学びましたが、最近構築したJASWRICで日本語の高大生&成人の特徴を調べると、その中の1つに、「犬が入ったバスケット」のようなものがあり、が・の、の観点で再分析できる可能性があるなと、気づきました。
国語研究所関連の研究会はいつも刺激的で、新しい研究のヒントをもらえます。
研究室で作成していた新しいコーパスJASWRICについて紹介発表を行いました。


