甲南女子中高の新高1生の皆さんを対象に、探究学習の導入講演を行いました。
会場は神戸六甲アイランドのオルビスホール。

写真はホールのウェブサイトより http://www.rokko-island.com/convention/15
wikiで調べると完成は1997年3月。バブルはすでにはじけていた時期ですが、ちょっとバブルの名残を感じさせる、こういう尖ったデザインの建物はその後少なくなったような気がします。
甲南女子中高の新高1生の皆さんを対象に、探究学習の導入講演を行いました。
会場は神戸六甲アイランドのオルビスホール。
wikiで調べると完成は1997年3月。バブルはすでにはじけていた時期ですが、ちょっとバブルの名残を感じさせる、こういう尖ったデザインの建物はその後少なくなったような気がします。
研究室がお世話をしているジャーナル2本が年度末ぎりぎりに公刊されました。
1)統計数理研究所共同研究リポート(ISM) No. 469
https://da.lib.kobe-u.ac.jp/da/kernel/cate_browse/?codeno=002&schemaid=30000&catecode=002089
2)Learner Corpus Studies in Asia and the World(LCSAW) No. 6
https://da.lib.kobe-u.ac.jp/da/kernel/cate_browse/?codeno=002&schemaid=30000&catecode=002007
・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・
いずれも、神戸大の電子アーカイブkernelをプラットフォームとしての発刊です。電子アーカイブは、すでに出た論文のバックアップ置き場?というイメージがありますが、新規の学術出版の刊行媒体としても非常に有益です。出版経費が高騰する中、こうした形での論文公刊は、これから広がっていくかもしれません。
今回、図書館の方と相談し、それぞれのジャーナルを紹介する短い文章を載せていただきました。これで、ジャーナルの来歴や性質などが同時に示せることとなり感謝しています。
表記に参加しました。
■ 開催日時
時間:2024/3/24 15:00~17:00
場所:国立国語研究所
■ 発表内容
1)建石始先生 (神戸女学院大学)「話題は類義語分析に使える」
2)橋本直幸先生(福岡女子大学)「日本語教材と話題 ―読解教材データベースと教材コーパスの作成-」
・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・
大変刺激的な発表で大いに勉強になりました。
国語研にはかつては頻繁にお伺いしていたのですが、コロナでイベントの大半が遠隔になり、コロナ収束後も遠隔のままのイベントが多いなかで、わたしにとっては、コロナ後初の立川訪問でした。研究会開始前に、参加者が各地のお菓子を持ち寄って談笑する姿など、対面ならではのひととき、久しぶりで懐かしく楽しみました。

2024年の2月ごろから、文化庁の日本語教師養成・研修推進拠点整備事業 の申請の責任者をやっていました。短期での申請で、いろいろと大変だったのですが、ご賛同くださる機関も多く、無事に申請にこぎつけ、先日採択をいただきました。
本日は顔合わせということで、皆さんとオンラインでお目にかかることができ、いよいよ始まるんだなという感慨を持ったところです。
他機関の専門家の皆様に教えを受けながら、地域の日本語教育の振興に少しでもお役に立てばと思っています。
ジャーナル特集号の執筆者の打ち合わせ会議に出席しました。
今回はこれから2年以上かけてということで、なんとも壮大なプロジェクトですが、 他の皆さんの足手まといにならぬよう、テーマ選定に取り組んでいきたいと思います。
*********
席上、面白かったのが、締め切りに関する意見交換で、同じ言語学者でも、分野によって、大げさに言うと、
(A)与えられた締め切りは死守する。締め切りとはまさしく"dead (or alive)" lineだ
(B)締め切りはただの目安。書き上がったときが自分にとっての締め切りだ
ぐらい、異なるとらえかたがありそうです。私見ですが、教育系の人は、(A)が多い気がしますし、わたしもたぶんその一人です。まあ、学生に遅刻したら10点引き、というようなことを毎日言っているからでしょうか。。。
科研で作っていた表記システムがリリースされました。

(1)英語テキスト&日本語テキストに対応
(2)オンラインで稼働するのでOSを問わない
(3)どのファイルにどの語が何回出ているかを一覧表示する「統合語彙頻度表」を作成できる
(4)表層形、表層形+品詞、語彙素、語彙素+品詞の4モードの出力に対応
といった特徴を持ちます。
単語ごとにレンジ(出現するファイル数)を比較したり、多変量解析のベースデータを作ったりする際に便利ではないかと存じます。開発版のため、お気づきの点があれば、ご教示いただけますと幸いです。
表記で講演を行いました。
第2部 ワークショップ 14:50-15:50
「森を見ながら木を見る」コーパスデータ処理方法の提案―英語・日本語の複数テキストから形態素解析済み統合頻度表を自動作成するEJ-WFTGの開発―
(石川慎一郎 神戸大学教授)
・・・・・・・・・・・・・・・・・・・
概要
【森から木へ】 ESP研究,史的言語研究,社会言語研究,習得研究など,言語変種間の差異の解明を目指す研究においては,集めたテキスト資料を特定の観点(ジャンル,時代,発話環境,母語・習熟度など)で群化してマージし,マージデータ間で計量的な比較を行って,特定変種の特徴語や特徴表現を抽出するアプローチが広くとられています。この場合,研究の関心は,変種というまとまり,たとえて言えば,1つの森に向けられていることになります。しかし,森の実態は雑多な樹木の集合であり,その中には,高い木もあれば低い木もあり,常緑樹もあれば落葉樹もあることでしょう。このことをふまえれば,言語変種研究においても,「森を見ながら木を見る」,つまりは,群の情報を保ったまま個体データを観察するというアプローチが重要になってきます。
【複数テキストデータからの統合頻度表の作成】 こうした立場に立つ場合,まず必要になるのは,数十種,時には,数百種におよぶ個別テキストごとに,そこに含まれるすべての語の頻度を調べ,それらを全テキスト間で相互比較できるようにした「統合語彙表」の作成です。しかし,個別テキストから作成した頻度表を,エクセル上で加工して1つの巨大な「統合頻度表」に仕上げていくのは,手作業では膨大な時間がかかります。また,語彙頻度を扱う場合は,出現形(表層形,書字形,表記形)と集約形(語彙素,レマ)といった単位の違い,さらには,個々の語の品詞にも着目する必要がありますが,これらの処理もきわめて煩瑣なものです。
【EJWFTG】そこで,石川研究室では,一連の作業を自動化するEnglish/Japanese Word Frequency Table Generator(EJWFTG)を開発・公開しました。EJWFTGは,(1)日本語・英語の2言語に対応し、(2)OS環境を問わず稼働し、(3)基本形から集約形への変換、(4)品詞情報の付与、の一連の作業を自動処理する統合頻度表作成ツールです。EJWFTGは、Google Colaboratoryの機能を使って作成されており、Pythonで処理が行われます。EJWFTGは,ESP研究者はもちろん,史的言語研究者,社会言語研究者,SLAや学習者コーパスの研究者など,何らかの形で変種の問題を扱う幅広い研究者にとって有益なツールになると思います。なお、EJWFTGは今尾康裕氏のCasualConcの機能にインスパイアされて開発されました。
【ワークショップ】 ワークショップでは,まず,筆者自身の過去の研究(とくにコーパスを用いた性差研究)を振り返りつつ,「森を見ながら木を見る」アプローチの重要性についてお話します。続いて,EJWFTGの使用法をハンズオンで解説します。その後,ESP分野のサンプルデータ(当日配布)から実際に統合頻度表を作成してみます。余裕があれば,フリーの統計処理ツールを用い(当日配布),統合頻度表をベースとして,クラスター分析や対応分析を実行する方法も学びます。当日は各自にパソコンをご持参いただき,一連の作業をご自身で体験いただければと思います。おそらく1時間で,EJWFTGでの処理から多変量解析までの処理の流れを身につけていただけるのではと思います。受講にあたり,特段の前提知識は不要ですが,院生の方などで,こうした処理の経験がまったくない場合は,語彙論の基本的な枠組み,とくに,出現形と集約形の違い,単語の品詞判定の方式などについて,少しだけ学んでおいていただけると当日の理解が早まるかと思います(たとえば,石川2023『ベーシックコーパス言語学(2版)』の7.1.3~7.16などを参照)。また,3月末以降,復習用資料として,下記がオンラインで読めるようになる予定です。
石川慎一郎(in press)「『森を見ながら木を見る』学習者コーパス研究の意義―複数テキストから統合頻度表を自動作成するEJWFTG開発の狙い―」『統計数理研究所共同研究リポート』469, 1-22. https://x.gd/WoiEV
表記に参加し、講話を行いました。探究の指導では多くの高校に出かけていますが、今回の発表は研究水準が抜群に高く、非常に感銘を受けました。英語も立派で、SSHの掲げる理念を非常に良い形で体現された発表だったと思います。

特に印象に残ったのは、同校OB、OGの大学生(大学院生)が研究サポーターとして大きな役割を果たしていたことです。英語質疑における彼らの鋭い質問にも感心しました。
SSHのまさに先端を磨くような加古川東の先駆的な取り組みが、今後、さらに大きな実りをあげるよう大いに期待したいところです。
・・・・・・・・・・・・・・・・・・・・・・・
加古川は、祖母の生地であり(記憶があいまいですが)、おそらくはそのために、幼児期に、何度か、加古川の鶴林寺(かくりんじ)を訪ねた記憶があります。
ということで、発表会の前に、40年以上?ぶりとなる鶴林寺訪問をしてきました。



表記(オンライン)に参加しました。
当日のプログラムはこちら。
ポスター発表では、下記の2本が特に勉強になりました。
柏野和佳子(国語研究所)「「要するに」は何を要しているかーCEJCを用いてー」
丸山直子(東京女子大学)「話し言葉の副助詞・係助詞ーCSJ,CEJC,CEJC-childを用いてー」
会話コーパスの場合、物理的なデータ量の制約から、そもそも出てこない語彙や表現も少なくないため、研究テーマをうまく見つけることが一般のコーパス研究以上に大事になります。その意味で、つなぎことばや助詞に注目するアプローチは会話コーパスの良さを引き出す有効な切り口だと思われます。
表記に参加しました。 久々の対面学会ということで、刺激的でした。Zoomでも質問はできるのですが、やはり、直接顔を見て、意見交換ができるのが対面学会の良さだと改めて感じました。
当日の発表リスト
王凱男(岡山大学大学院)現代若者の自然会話における接続詞の使用実態―性差に着目して―
李欣然(中国・北京外国語大学大学院)学習者の気づき機能が日本語の会話習得に与える影響
浦井智司(早稲田大学大学院)非母語話者教師の考えるオンライン化できない日本語母語教師の役割―コロナ禍に始まったオンライン授業を中心に―
林燕燕(東京外国語大学大学院)中国の日本語教科書における漢語動作名詞を用いた機能動詞結合の提示状況に関する一考察―教科書間の比較を中心に―
劉藝寒(東京都立大学大学院)読解指導を受けた後に中国人日本語学習者による同一文章の要約文に現れた変化―残存内容と表現形式に着目して―
孫守乾(東京都立大学大学院)日本語卒業論文の最終章における構成要素とその指導の考察―指導教員に対する半構造化インタビューから―
目黒裕将(エイム奈良国際アカデミー) 中国の日本語専攻大学生による言語分野の卒業論文テーマ―X大学を対象としたテキストマイニングを用いた卒業論文題目分析―
邢修強(中国・上海外国語大学大学院)中国人日本語学習者の「~的」の誤用分析
劉志毅(早稲田大学大学院)日本語簿記の専門用語の特徴と授業導入の最適な時期について―日本語学の知見を援用した「日本語+α」人材の育成を目指して―
蔡苗苗(大阪大学大学院)ピア・レスポンス活動による学習者間の知識構築過程の分析―中国人日本語学習者に対する縦断的調査をもとに―
崔英才(中国・淮陰師範学院講師)オンラインの接触場面会話におけるスピーチスタイルシフト―中国国内の学習者の習得問題を中心に―
郭テイテイ(関西大学大学院)断り場面における中国語を母語とする日本語学習者の言いさし表現の使用実態―日本語母語話者と比較して
北京外大大学院からの研究生である蒋钰豪氏が、半年間の日本での研究生活を終えて帰国されることになりました。
コーパスを用いた批判的談話分析という意欲的な課題を遂行され、短期間でしたが、立派な成果を挙げられました。



表記に参加しました。
Chat GPTに関する基調講演(水本篤先生)は非常に啓発的で、いろいろと考えさせらえました。とくに、「Chat GPTは単純な語数計算に弱い」というのは気づかなかった盲点で、このあたり、Chat GPTのアルゴリズムの不思議を感じます。
学会ウェブサイトでの報告ページはこちら。
**************
今回の学会ではもう1つ嬉しい出会いがありました。2007年ごろ、神戸大の修士で勉強され、私のゼミにも出てくれていた中国からの留学生が、その後、博士号をとって、日本の大学の教員になっておられました。17年ぶりの再会ですが、会った瞬間、17年前の楽しかったゼミ風景と直結しました。ますますのご活躍を祈ります。
クウェート大学(クウェートシティ)で開催された表記学会において、研究発表を行いました。
Shin Ishikawa (Kobe U)
Automated Assessment of Asian EFL Learners’ L2 English Speeches and Essays: A Comparison of Lexus-based and Lexicogrammar-based approaches

GRA v2.1を用いた自動スコア推定の試みです。




サンプルファイル
ICNALE_WE_CHN_PTJ0_001_B1_1
1)Antconcでの語数確認


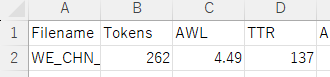
4) MATでTTR基準を思い切って10にしてみる(この場合、最初の10語だけを数えるのか?)

5) MATでTTR基準を実際の272語より長い400語にしてみる。

結論
1)TTRは誤解のあるかきかたで、「別途指定したサンプル長におけるタイプ数」というのが正しい
2)MATが聞いている「TTR指定」というのは、タイプ(異なり語数)を数えるための、テキスト冒頭からの分析対象長の指定、と理解したほうがよい。
3)たとえば、100語、1000語、1万語のテキストを同時分析する場合であれば、最小の100語にそろえておくのが正解。もし1万語に設定すると、100語や1000語ファイルは基本条件で圧倒的に不利になってしまう。しかも基準値は出力のエクセルに記録されないので、分析者もチェックの手段がなくなる。ただし、100語に設定した場合、たとえば500人の作文をマージした群データなどを見ているのであれば、冒頭の1人目の作文(の一部)しか見ていないことになる。